
Neuralnet Basic 03
KEARS 창시자에게 배우는 딥러닝 - 3장 -01 이진분류문제
Basic 2 에서, Mnist를 했다면, 여기서는 간단한 영화리뷰에 대해서, binaray classfication을 수행한다. 책 관련 Blog 로 이동
import tensorflow as tf
from keras.backend import tensorflow_backend as K
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
K.set_session(tf.Session(config=config))
Using TensorFlow backend.
import keras
keras.__version__
'2.2.4'
from keras.datasets import imdb
## num_words=10000 는 훈련데이터에서, 자주 사용하는 단어 1만개만 사용하겠다는 의미임
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
——————————–데이터 내용 파악 start————————————————–
print("train_data.shape",train_data.shape)
print("train_labels.shape",train_labels.shape)
print("test_data.shape",test_data.shape)
print("test_labels",test_labels.shape)
train_data.shape (25000,)
train_labels.shape (25000,)
test_data.shape (25000,)
test_labels (25000,)
언뜻 보기엔 2D tensor 같지만, np.array로 1개의 벡터 안에, 원소가 list 형태임. 이대로는 keras 모델에 집어넣을 수 없음
print(type(train_data))
print(train_data.ndim) ## 1D tensor
<class 'numpy.ndarray'>
1
train_data[12].ndim
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-d5031e034ebb> in <module>
----> 1 train_data[12].ndim
AttributeError: 'list' object has no attribute 'ndim'
print(len(train_data[12]))
print(type(train_data[12]))
train_data[12][0:10] ## 25번째 데이터의 구성을 보면, 총 142개의 단어로 되어 있고, 0~9번째까지의 단어는 하기와 같다.
117
<class 'list'>
[1, 13, 119, 954, 189, 1554, 13, 92, 459, 48]
print(len(train_data[25]))
train_data[25][0:10] ## 25번째 데이터의 구성을 보면, 총 142개의 단어로 되어 있고, 0~9번째까지의 단어는 하기와 같다.
142
[1, 14, 9, 6, 55, 641, 2854, 212, 44, 6]
max([max(sequence) for sequence in train_data]) ## num_words=10000 제한이 없었으면, 88586 단어의 데이터가 존재한다
9999
for line_idx in range(0,len(train_data)):
if (line_idx%5000)==0:
print(len(train_data[line_idx]))
## 보시다시피, 각 train_data 라인당 모두 길이가 다르다
218
124
118
281
252
원래의 영어단어로 바꾸기
# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다
word_index = imdb.get_word_index()
print(type(word_index),len(word_index))
word_index['faw'] ## faw 란 단어는 이 train 셋의 단어사전에서, index 번호가 88584 이다.
<class 'dict'> 88584
84994
# 정수 인덱스와 단어를 매핑하도록 뒤집습니다
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
reverse_word_index[77]
'will'
dictinary 깨알상식 dict.get(key, default = None)
Parameters
key − This is the Key to be searched in the dictionary.
default − This is the Value to be returned in case key does not exist.
# 리뷰를 디코딩합니다.
# 0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺍니다 (그렇게 구성된듯...내가 한게 아니니 원..어떤의미인줄은 알겠다.)
# 해당하는 값이 key 값(= i-3) 이 없으면,
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[25]])
train_data[25] 는 list 임으로 1개씩 뽑혀져 나온다. 이 값을 가지고, 원래 어떤 단어인지 유추한다.
decoded_review
'? this is a very light headed comedy about a wonderful family that has a son called pecker because he use to peck at his food pecker loves to take all kinds of pictures of the people in a small ? of ? ? and manages to get the attention of a group of photo art lovers from new york city pecker has a cute sister who goes simply nuts over sugar and is actually an addict taking ? of sugar from a bag there are scenes of men showing off the ? in their ? with ? movements and ? doing pretty much the same it is rather hard to keep your mind out of the ? with this film but who cares it is only a film to give you a few laughs at a simple picture made in 1998'
——————————–데이터 내용 파악 end————————————————–
신경망에는 list를 input data로 활용할수없기때문에, vector 로 바꾼다. 이때, Embedding 이나, one-hotencoding을 사용하는데, 여기서는 one-hotencoding을 활용한다.
print("train_data.shape",train_data.shape)
print("test_data.shape",test_data.shape)
train_data.shape (25000,)
test_data.shape (25000,)
앞서 언급했듯이, 현재는 1D tensor 이기에, 이대로는 넣을 수 없다. 따라서, 2D tensor , ndim=2, np.array type 으로 바꿔줘야 한다.
import numpy as np
def vectorize_sequences(sequences, dimension=10000): ## 처음 데이터를 불러올때부터, 높은 빈도수 10000 개로 제한했기때문
# 크기가 (len(sequences), dimension))이고 모든 원소가 0인 행렬을 만듭니다
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
# if i==100:
# print(i,type(sequence))
results[i, sequence] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만듭니다. 여기서 sequence 는 list type 이다.
## 즉 1개 행에서, 존재하는 모든 단어들을 그 위치에 1로서 원핫인코딩 때린다.
return results
# 훈련 데이터를 벡터로 변환합니다
x_train = vectorize_sequences(train_data)
# 테스트 데이터를 벡터로 변환합니다
x_test = vectorize_sequences(test_data)
print("after one-hot x_train.shape",x_train.shape)
print("after one-hot x_test.shape",x_test.shape)
after one-hot x_train.shape (25000, 10000)
after one-hot x_test.shape (25000, 10000)
print(type(train_labels))
<class 'numpy.ndarray'>
# 레이블을 벡터로 바꿉니다
## np.asarray 는 numpy 객체를 copy 생성하면서, numpy 형태로 변형한다.
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print(train_labels[0])
print(y_train[0])
1
1.0
신경망 모형

from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='sigmoid', input_shape=(10000,))) ## sigmoid, tahn
model.add(layers.Dense(16, activation='sigmoid'))
model.add(layers.Dense(1, activation='sigmoid'))
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
## 상기처럼 해도 되지만, 객체를 넣어서 불러와도 된다.
# from keras import losses
# from keras import metrics
# model.compile(optimizer=optimizers.RMSprop(lr=0.001),
# loss=losses.binary_crossentropy,
# metrics=[metrics.binary_accuracy])
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 2s 156us/step - loss: 0.6739 - acc: 0.5777 - val_loss: 0.6403 - val_acc: 0.7245
Epoch 2/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.6020 - acc: 0.8266 - val_loss: 0.5719 - val_acc: 0.8451
Epoch 3/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.5265 - acc: 0.8686 - val_loss: 0.5045 - val_acc: 0.8551
Epoch 4/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.4548 - acc: 0.8855 - val_loss: 0.4451 - val_acc: 0.8638
Epoch 5/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.3907 - acc: 0.8997 - val_loss: 0.3941 - val_acc: 0.8732
Epoch 6/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.3366 - acc: 0.9102 - val_loss: 0.3547 - val_acc: 0.8802
Epoch 7/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.2913 - acc: 0.9211 - val_loss: 0.3243 - val_acc: 0.8843
Epoch 8/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.2541 - acc: 0.9287 - val_loss: 0.3026 - val_acc: 0.8881
Epoch 9/20
15000/15000 [==============================] - 2s 114us/step - loss: 0.2237 - acc: 0.9360 - val_loss: 0.2897 - val_acc: 0.8872
Epoch 10/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1979 - acc: 0.9419 - val_loss: 0.2775 - val_acc: 0.8908
Epoch 11/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1763 - acc: 0.9491 - val_loss: 0.2718 - val_acc: 0.8919
Epoch 12/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1579 - acc: 0.9546 - val_loss: 0.2752 - val_acc: 0.8887
Epoch 13/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1420 - acc: 0.9597 - val_loss: 0.2719 - val_acc: 0.8904
Epoch 14/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1283 - acc: 0.9635 - val_loss: 0.2781 - val_acc: 0.8879
Epoch 15/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1164 - acc: 0.9677 - val_loss: 0.2784 - val_acc: 0.8894
Epoch 16/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.1055 - acc: 0.9722 - val_loss: 0.2863 - val_acc: 0.8878
Epoch 17/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.0962 - acc: 0.9753 - val_loss: 0.2917 - val_acc: 0.8863
Epoch 18/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.0868 - acc: 0.9783 - val_loss: 0.3020 - val_acc: 0.8842
Epoch 19/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.0791 - acc: 0.9806 - val_loss: 0.3094 - val_acc: 0.8847
Epoch 20/20
15000/15000 [==============================] - 2s 115us/step - loss: 0.0713 - acc: 0.9839 - val_loss: 0.3207 - val_acc: 0.8834
history_dict = history.history
history_dict.keys()
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# ‘bo’는 파란색 점을 의미합니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# ‘b’는 파란색 실선을 의미합니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
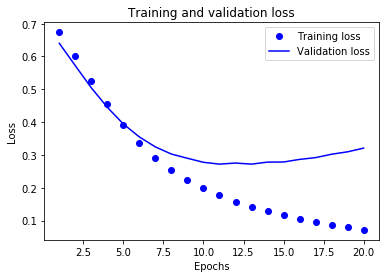
plt.clf() # 그래프를 초기화합니다
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
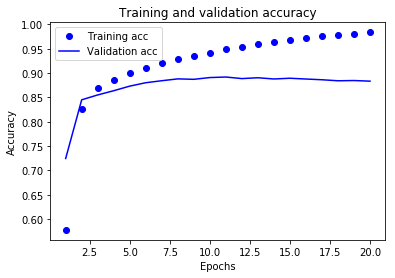
위 표 결과를 볼대, 과적합을 피하기 위해, epoch=4 에서부터, 적당히 잘라주면 된다.
model.fit(x_train, y_train, epochs=5, batch_size=512)
results = model.evaluate(x_test, y_test)
Epoch 1/5
25000/25000 [==============================] - 2s 71us/step - loss: 0.1664 - acc: 0.9446
Epoch 2/5
25000/25000 [==============================] - 2s 72us/step - loss: 0.1477 - acc: 0.9510
Epoch 3/5
25000/25000 [==============================] - 2s 71us/step - loss: 0.1345 - acc: 0.9586
Epoch 4/5
25000/25000 [==============================] - 2s 71us/step - loss: 0.1244 - acc: 0.9618
Epoch 5/5
25000/25000 [==============================] - 2s 71us/step - loss: 0.1153 - acc: 0.9658
25000/25000 [==============================] - 3s 101us/step
results ## relu -> sigmoid 가 약간 더 acc 가 더 높게 나옴
[0.3637210688018799, 0.87012]
y_proba = model.predict(x_test)
y_proba
array([[0.02142894],
[0.99465084],
[0.48729646],
...,
[0.04120988],
[0.0253683 ],
[0.6526566 ]], dtype=float32)
len(y_proba) ## test set의 결과표
25000
상기까지의 현재 모델 요약
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 16) 160016
_________________________________________________________________
dense_2 (Dense) (None, 16) 272
_________________________________________________________________
dense_3 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
변경Case01. 은닉 layer을 더 추가한다면?
model_01 = models.Sequential()
model_01.add(layers.Dense(16, activation='sigmoid', input_shape=(10000,))) ## sigmoid, tahn
model_01.add(layers.Dense(16, activation='sigmoid'))
model_01.add(layers.Dense(16, activation='sigmoid')) ## 추가 1
model_01.add(layers.Dense(16, activation='sigmoid')) ## 추가 2
model_01.add(layers.Dense(1, activation='sigmoid'))
model_01.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 16) 160016
_________________________________________________________________
dense_5 (Dense) (None, 16) 272
_________________________________________________________________
dense_6 (Dense) (None, 16) 272
_________________________________________________________________
dense_7 (Dense) (None, 16) 272
_________________________________________________________________
dense_8 (Dense) (None, 1) 17
=================================================================
Total params: 160,849
Trainable params: 160,849
Non-trainable params: 0
_________________________________________________________________
model_01.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
rslt_01 = model_01.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 2s 133us/step - loss: 0.6960 - acc: 0.5035 - val_loss: 0.6911 - val_acc: 0.4968
Epoch 2/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.6877 - acc: 0.6026 - val_loss: 0.6837 - val_acc: 0.6322
Epoch 3/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.6745 - acc: 0.8247 - val_loss: 0.6648 - val_acc: 0.7966
Epoch 4/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.6445 - acc: 0.8663 - val_loss: 0.6264 - val_acc: 0.8527
Epoch 5/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.5913 - acc: 0.8851 - val_loss: 0.5665 - val_acc: 0.8652
Epoch 6/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.5178 - acc: 0.8976 - val_loss: 0.4945 - val_acc: 0.8742
Epoch 7/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.4354 - acc: 0.9081 - val_loss: 0.4233 - val_acc: 0.8792
Epoch 8/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.3565 - acc: 0.9180 - val_loss: 0.3634 - val_acc: 0.8836
Epoch 9/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.2898 - acc: 0.9285 - val_loss: 0.3208 - val_acc: 0.8875
Epoch 10/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.2383 - acc: 0.9369 - val_loss: 0.2951 - val_acc: 0.8909
Epoch 11/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.2005 - acc: 0.9447 - val_loss: 0.2869 - val_acc: 0.8915
Epoch 12/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.1719 - acc: 0.9515 - val_loss: 0.2828 - val_acc: 0.8920
Epoch 13/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.1502 - acc: 0.9580 - val_loss: 0.2882 - val_acc: 0.8911
Epoch 14/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.1333 - acc: 0.9645 - val_loss: 0.2925 - val_acc: 0.8920
Epoch 15/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.1194 - acc: 0.9683 - val_loss: 0.3065 - val_acc: 0.8895
Epoch 16/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.1075 - acc: 0.9721 - val_loss: 0.3176 - val_acc: 0.8874
Epoch 17/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.0963 - acc: 0.9769 - val_loss: 0.3295 - val_acc: 0.8861
Epoch 18/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.0863 - acc: 0.9800 - val_loss: 0.3413 - val_acc: 0.8858
Epoch 19/20
15000/15000 [==============================] - 2s 116us/step - loss: 0.0791 - acc: 0.9821 - val_loss: 0.3537 - val_acc: 0.8867
Epoch 20/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0721 - acc: 0.9849 - val_loss: 0.3673 - val_acc: 0.8869
rslt_01_dict = rslt_01.history
rslt_01_dict.keys()
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
acc = rslt_01.history['acc']
val_acc = rslt_01.history['val_acc']
loss = rslt_01.history['loss']
val_loss = rslt_01.history['val_loss']
epochs = range(1, len(acc) + 1)
# ‘bo’는 green 점을 의미합니다
plt.plot(epochs, loss, 'go', label='Training loss')
# ‘b’는 green 실선을 의미합니다
plt.plot(epochs, val_loss, 'g', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
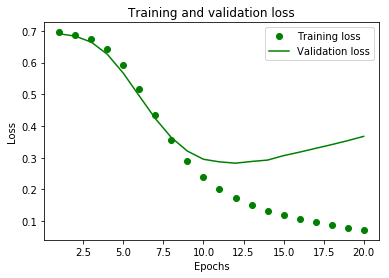
plt.clf() # 그래프를 초기화합니다
acc = rslt_01_dict['acc']
val_acc = rslt_01_dict['val_acc']
plt.plot(epochs, acc, 'go', label='Training acc')
plt.plot(epochs, val_acc, 'g', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
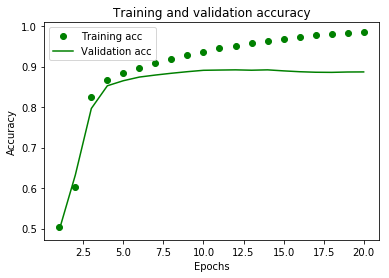
layer 를 많이 주니 Training 결과값만 더 좋아진다. layer 가 늘어날수록, 좀 더 과적합이 생기는데 acc 나, loss 값이 좀 더 좋아진다. 즉 성능이 향상된다. 과적합은 epoch 5보다는 더 큰 8~9 에서, 멈추는게 적절해 보인다.
변경Case02. 은닉 layer에 node 를 더 추가한다면?
16 -> 64 로 4배로 node 증가시킴
model_02 = models.Sequential()
model_02.add(layers.Dense(64, activation='sigmoid', input_shape=(10000,))) ## sigmoid, tahn ## 16 -> 64 로
model_02.add(layers.Dense(64, activation='sigmoid'))
model_02.add(layers.Dense(1, activation='sigmoid'))
model_02.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
rslt_02 = model_02.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 2s 143us/step - loss: 0.6392 - acc: 0.7230 - val_loss: 0.5619 - val_acc: 0.7860
Epoch 2/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.4595 - acc: 0.8677 - val_loss: 0.3970 - val_acc: 0.8673
Epoch 3/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.3171 - acc: 0.8991 - val_loss: 0.3135 - val_acc: 0.8817
Epoch 4/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.2369 - acc: 0.9213 - val_loss: 0.3066 - val_acc: 0.8725
Epoch 5/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.1911 - acc: 0.9337 - val_loss: 0.2716 - val_acc: 0.8927
Epoch 6/20
15000/15000 [==============================] - 2s 118us/step - loss: 0.1588 - acc: 0.9467 - val_loss: 0.2783 - val_acc: 0.8882
Epoch 7/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.1334 - acc: 0.9569 - val_loss: 0.2830 - val_acc: 0.8869
Epoch 8/20
15000/15000 [==============================] - 2s 118us/step - loss: 0.1157 - acc: 0.9640 - val_loss: 0.2864 - val_acc: 0.8871
Epoch 9/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0980 - acc: 0.9700 - val_loss: 0.3016 - val_acc: 0.8842
Epoch 10/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0846 - acc: 0.9758 - val_loss: 0.3153 - val_acc: 0.8835
Epoch 11/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0726 - acc: 0.9795 - val_loss: 0.3432 - val_acc: 0.8817
Epoch 12/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0616 - acc: 0.9843 - val_loss: 0.3637 - val_acc: 0.8805
Epoch 13/20
15000/15000 [==============================] - 2s 118us/step - loss: 0.0524 - acc: 0.9875 - val_loss: 0.3749 - val_acc: 0.8793
Epoch 14/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0444 - acc: 0.9894 - val_loss: 0.3987 - val_acc: 0.8775
Epoch 15/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0368 - acc: 0.9924 - val_loss: 0.4284 - val_acc: 0.8772
Epoch 16/20
15000/15000 [==============================] - 2s 118us/step - loss: 0.0295 - acc: 0.9942 - val_loss: 0.4489 - val_acc: 0.8708
Epoch 17/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0252 - acc: 0.9954 - val_loss: 0.4814 - val_acc: 0.8668
Epoch 18/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0207 - acc: 0.9968 - val_loss: 0.5006 - val_acc: 0.8680
Epoch 19/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0163 - acc: 0.9976 - val_loss: 0.5325 - val_acc: 0.8713
Epoch 20/20
15000/15000 [==============================] - 2s 117us/step - loss: 0.0137 - acc: 0.9984 - val_loss: 0.5574 - val_acc: 0.8701
rslt_02_dict = rslt_02.history
rslt_02_dict.keys()
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
acc = rslt_02_dict['acc']
val_acc = rslt_02_dict['val_acc']
loss = rslt_02_dict['loss']
val_loss = rslt_02_dict['val_loss']
epochs = range(1, len(acc) + 1)
# ‘bo’는 green 점을 의미합니다
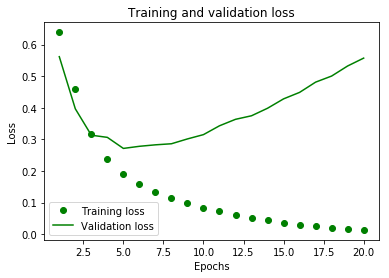
plt.plot(epochs, loss, 'go', label='Training loss')
# ‘b’는 green 실선을 의미합니다
plt.plot(epochs, val_loss, 'g', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf() # 그래프를 초기화합니다
plt.plot(epochs, acc, 'go', label='Training acc')
plt.plot(epochs, val_acc, 'g', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
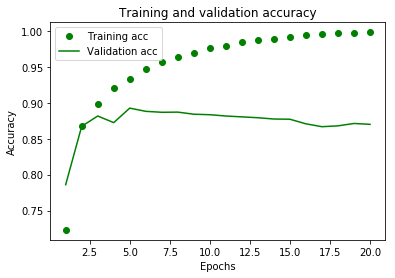
node 를 많이 주니 성능이 더 떨어져 보인다. 내 생각에는 node 가 많아지면, 결국 출력 값이 많아지기 때문에, 오히려 모델결과에 유리하지 않은 것 같다.
model class 에서, predict 와 evaluate
Returns the loss value & metrics values for the model in test mode.
e_rslt = model_02.evaluate(x_test, y_test)
25000/25000 [==============================] - 2s 99us/step
print(type(e_rslt),len(e_rslt))
e_rslt ## loss 값고, acc 값 을 보여준다.
<class 'list'> 2
[0.6089701456546783, 0.85588]
y_proba = model_02.predict(x_test)
print(y_proba.shape,type(y_proba))
(25000, 1) <class 'numpy.ndarray'>
Comments