
Neuralnet Basic 04
KEARS 창시자에게 배우는 딥러닝 - 3장 -02 다중분류문제
앞에서, 이진분류문제를 해결했다면, 여기서는 기사뉴스에 대해서, 다중분류 모델을 풀어본다. 책 관련 Blog 로 이동
## local PC 에서, gpu 메모리를 다른 프로세서가 선점하고 있을때, 다시 설정해주는 코드임
import tensorflow as tf
from keras.backend import tensorflow_backend as K
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
K.set_session(tf.Session(config=config))
Using TensorFlow backend.
import keras
keras.__version__
'2.2.4'
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
Downloading data from https://s3.amazonaws.com/text-datasets/reuters.npz
2113536/2110848 [==============================] - 2s 1us/step
——————————–데이터 내용 파악 start————————————————–
print("train_data.shape",train_data.shape)
print("train_labels.shape",train_labels.shape)
print("test_data.shape",test_data.shape)
print("test_labels",test_labels.shape)
train_data.shape (8982,)
train_labels.shape (8982,)
test_data.shape (2246,)
test_labels (2246,)
print(len(train_data[25]))
train_data[25][0:10] ## 25번째 데이터의 구성을 보면, 총 142개의 단어로 되어 있고, 0~9번째까지의 단어는 하기와 같다.
110
[1, 144, 62, 2115, 451, 82, 5, 37, 38, 399]
max([max(sequence) for sequence in train_data]) ## num_words=10000 제한이 없었으면, 88586 단어의 데이터가 존재한다
9999
for line_idx in range(0,len(train_data)):
if (line_idx%1000)==0:
print(len(train_data[line_idx]))
## 보시다시피, 각 train_data 라인당 모두 길이가 다르다
87
626
34
17
187
243
65
41
267
원래의 영어단어로 바꾸기
# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다
word_index = reuters.get_word_index()
Downloading data from https://s3.amazonaws.com/text-datasets/reuters_word_index.json
557056/550378 [==============================] - 1s 2us/step
print(type(word_index),len(word_index))
word_index['faw'] ## faw 란 단어는 이 train 셋의 단어사전에서, index 번호가 88584 이다.
<class 'dict'> 30979
12050
# 정수 인덱스와 단어를 매핑하도록 뒤집습니다
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
reverse_word_index[1]
'the'
dictinary 깨알상식 dict.get(key, default = None)
Parameters
key − This is the Key to be searched in the dictionary.
default − This is the Value to be returned in case key does not exist.
# 리뷰를 디코딩합니다.
# 0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺍니다 (그렇게 구성된듯...내가 한게 아니니 원..어떤의미인줄은 알겠다.)
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[25]])
decoded_review
"? there were 106 200 tonnes of u s corn shipped to the soviet union in the week ended march 26 according to the u s agriculture department's latest export sales report there were no wheat or soybean shipments during the week the ussr has purchased 2 65 mln tonnes of u s corn as of march 26 for delivery in the fourth year of the u s ussr grain agreement total shipments in the third year of the u s ussr grains agreement which ended september 30 amounted to 152 600 tonnes of wheat 6 808 100 tonnes of corn and 1 518 700 tonnes of soybeans reuter 3"
——————————–데이터 내용 파악 end————————————————–
신경망에는 list를 input data로 활용할수없기때문에, vector 로 바꾼다. 이때, Embedding 이나, one-hotencoding을 사용하는데, 여기서는 one-hotencoding을 활용한다.
print("train_data.shape",train_data.shape)
print("test_data.shape",test_data.shape)
train_data.shape (8982,)
test_data.shape (2246,)
import numpy as np
def vectorize_sequences(sequences, dimension=10000): ## 처음 데이터를 불러올때부터, 높은 빈도수 10000 개로 제한했기때문
# 크기가 (len(sequences), dimension))이고 모든 원소가 0인 행렬을 만듭니다
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
# if i==100:
# print(i,type(sequence))
results[i, sequence] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만듭니다. 여기서 sequence 는 list type 이다.
## 즉 1개 행에서, 존재하는 모든 단어들을 그 위치에 1로서 원핫인코딩 때린다.
return results
# 훈련 데이터를 벡터로 변환합니다
x_train = vectorize_sequences(train_data)
# 테스트 데이터를 벡터로 변환합니다
x_test = vectorize_sequences(test_data)
print("after one-hot x_train.shape",x_train.shape)
print("after one-hot x_test.shape",x_test.shape)
after one-hot x_train.shape (8982, 10000)
after one-hot x_test.shape (2246, 10000)
앞 부분과 다른게 있다면, label에 대해서, 변형이 필요하다 여기는 이진분류가 아니라, 46개의 분류를 가지고 있고, 최종 softmax 계층을 통해서, 나올것 역시 (n=batch_size크기,46) 이 될것이기 때문에, 원핫이코딩으로 labe 데이터를 바꿔줘야 한다.
print("train_labels.shape",train_labels.shape)
print("test_labels",test_labels.shape)
train_labels.shape (8982,)
test_labels (2246,)
직접 만들어도 되지만, 기왕이면, 있는 걸 사용하자
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# 훈련 레이블 벡터 변환
one_hot_train_labels = to_one_hot(train_labels)
# 테스트 레이블 벡터 변환
# one_hot_test_labels = to_one_hot(test_labels)
from keras.utils.np_utils import to_categorical
# one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
모델만들기
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
이 구조에서 주목해야 할 점이 두 가지 있습니다:
마지막 Dense 층의 크기가 46입니다. 각 입력 샘플에 대해서 46차원의 벡터를 출력한다는 뜻입니다. 이 벡터의 각 원소(각 차원)은 각기 다른 출력 클래스가 인코딩된 것입니다.
마지막 층에 softmax 활성화 함수가 사용되었습니다. MNIST 예제에서 이런 방식을 보았습니다. 각 입력 샘플마다 46개의 출력 클래스에 대한 확률 분포를 출력합니다. 즉, 46차원의 출력 벡터를 만들며 output[i]는 어떤 샘플이 클래스 i에 속할 확률입니다. 46개의 값을 모두 더하면 1이 됩니다.
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 1s 129us/step - loss: 2.5322 - acc: 0.4955 - val_loss: 1.7208 - val_acc: 0.6120
Epoch 2/20
7982/7982 [==============================] - 1s 70us/step - loss: 1.4452 - acc: 0.6879 - val_loss: 1.3459 - val_acc: 0.7060
Epoch 3/20
7982/7982 [==============================] - 1s 70us/step - loss: 1.0953 - acc: 0.7651 - val_loss: 1.1708 - val_acc: 0.7430
Epoch 4/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.8697 - acc: 0.8165 - val_loss: 1.0793 - val_acc: 0.7590
Epoch 5/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.7034 - acc: 0.8472 - val_loss: 0.9844 - val_acc: 0.7810
Epoch 6/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.5667 - acc: 0.8802 - val_loss: 0.9411 - val_acc: 0.8040
Epoch 7/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.4581 - acc: 0.9048 - val_loss: 0.9083 - val_acc: 0.8020
Epoch 8/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.3695 - acc: 0.9231 - val_loss: 0.9363 - val_acc: 0.7890
Epoch 9/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.3032 - acc: 0.9315 - val_loss: 0.8917 - val_acc: 0.8090
Epoch 10/20
7982/7982 [==============================] - 1s 69us/step - loss: 0.2537 - acc: 0.9414 - val_loss: 0.9071 - val_acc: 0.8110
Epoch 11/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.2187 - acc: 0.9471 - val_loss: 0.9177 - val_acc: 0.8130
Epoch 12/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.1873 - acc: 0.9508 - val_loss: 0.9027 - val_acc: 0.8130
Epoch 13/20
7982/7982 [==============================] - 1s 71us/step - loss: 0.1703 - acc: 0.9521 - val_loss: 0.9323 - val_acc: 0.8110
Epoch 14/20
7982/7982 [==============================] - 1s 71us/step - loss: 0.1536 - acc: 0.9554 - val_loss: 0.9689 - val_acc: 0.8050
Epoch 15/20
7982/7982 [==============================] - 1s 72us/step - loss: 0.1390 - acc: 0.9560 - val_loss: 0.9686 - val_acc: 0.8150
Epoch 16/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.1313 - acc: 0.9560 - val_loss: 1.0220 - val_acc: 0.8060
Epoch 17/20
7982/7982 [==============================] - 1s 71us/step - loss: 0.1217 - acc: 0.9579 - val_loss: 1.0254 - val_acc: 0.7970
Epoch 18/20
7982/7982 [==============================] - 1s 69us/step - loss: 0.1198 - acc: 0.9582 - val_loss: 1.0430 - val_acc: 0.8060
Epoch 19/20
7982/7982 [==============================] - 1s 70us/step - loss: 0.1138 - acc: 0.9597 - val_loss: 1.0955 - val_acc: 0.7970
Epoch 20/20
7982/7982 [==============================] - 1s 69us/step - loss: 0.1111 - acc: 0.9593 - val_loss: 1.0674 - val_acc: 0.8020
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 640064
_________________________________________________________________
dense_2 (Dense) (None, 64) 4160
_________________________________________________________________
dense_3 (Dense) (None, 46) 2990
=================================================================
Total params: 647,214
Trainable params: 647,214
Non-trainable params: 0
_________________________________________________________________
## 모델파일 저장
from keras.utils import plot_model
plot_model(model)
import matplotlib.pyplot as plt
# 학습 정확성 값과 검증 정확성 값을 플롯팅 합니다.
plt.plot(history.history['acc']) ## x range 는 생략하고 그릴 수 있다.
plt.plot(history.history['val_acc']) ##
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper left')
plt.show()
# 학습 손실 값과 검증 손실 값을 플롯팅 합니다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper left')
plt.show()
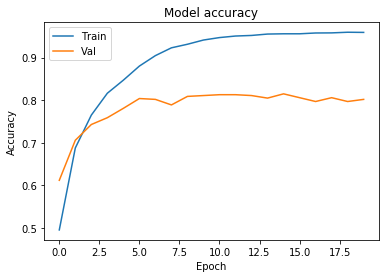
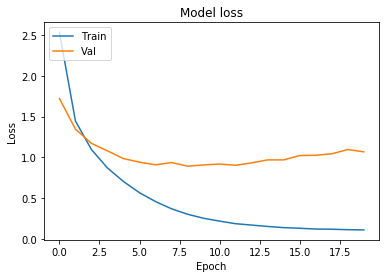
epoch == 6 를 넘거가면서, 과적합 경향이 보이고, 있다.
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=6,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
Train on 7982 samples, validate on 1000 samples
Epoch 1/6
7982/7982 [==============================] - 1s 102us/step - loss: 2.5398 - acc: 0.5226 - val_loss: 1.6733 - val_acc: 0.6570
Epoch 2/6
7982/7982 [==============================] - 1s 72us/step - loss: 1.3712 - acc: 0.7121 - val_loss: 1.2758 - val_acc: 0.7210
Epoch 3/6
7982/7982 [==============================] - 1s 72us/step - loss: 1.0136 - acc: 0.7781 - val_loss: 1.1303 - val_acc: 0.7530
Epoch 4/6
7982/7982 [==============================] - 1s 73us/step - loss: 0.7976 - acc: 0.8251 - val_loss: 1.0539 - val_acc: 0.7590
Epoch 5/6
7982/7982 [==============================] - 1s 72us/step - loss: 0.6393 - acc: 0.8624 - val_loss: 0.9754 - val_acc: 0.7920
Epoch 6/6
7982/7982 [==============================] - 1s 73us/step - loss: 0.5124 - acc: 0.8921 - val_loss: 0.9102 - val_acc: 0.8140
2246/2246 [==============================] - 0s 98us/step
results ## 평균적으로 77% 의 정확도를 보인다.
[0.9999364437211972, 0.7760463045944832]
## 만약 무작위로 정확도를 맞춘다면 몇 % 일까?
import numpy as np
test_labels_copy = test_labels.copy()
np.random.shuffle(test_labels_copy)
float(np.sum(np.array(test_labels) == np.array(test_labels_copy))) / len(test_labels)
0.18210151380231523
참고삼아 모델이 좋다는 걸 보려주려고 만든 저 코드를 적은것임
y_proba = model.predict(x_test)
print(len(y_proba),y_proba[0]) ## 46개 class 에 대해, 확률값을 보여줌
2246 [5.6932033e-05 4.4352922e-04 3.0528088e-04 7.4149567e-01 2.2675942e-01
1.9369566e-06 2.7999043e-04 7.2869065e-05 9.5376140e-03 3.9166669e-05
1.2232029e-04 4.1087889e-03 1.4417898e-04 5.9132435e-04 2.1871190e-05
6.0140865e-05 2.9191682e-03 1.0249711e-03 1.4333625e-03 1.2888955e-03
2.3878599e-03 7.0721621e-04 3.7400765e-05 9.3906239e-04 8.0006139e-05
1.1919800e-03 5.3427688e-05 8.2510865e-05 8.0199483e-05 1.6487487e-04
7.8425917e-04 7.2598696e-04 7.3957883e-05 4.5468420e-05 1.1143668e-04
2.7588221e-05 1.8611869e-04 6.8536981e-05 8.0922749e-05 3.4679004e-04
1.4818282e-04 7.7453448e-04 5.9704807e-06 1.4402656e-04 2.6564956e-05
1.7750399e-05]
y_proba[0].sum(axis=0) ## 확률값이니깐, 합쳐서 1
1.0000001
np.argmax(y_proba[0]) ## class 3 으로 분류한다.
3
지금까지는 label 를 one-hot 으로 인코딩 했는데, 만약, 그냥 사용하려면, 하기와 같이 하면 된다.
one_hot_test_labels[0]
array([0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
print(type(train_labels))
print(type(test_labels))
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
# loss='categorical_crossentropy',
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
test_labels[0]
3
partial_y_train_sparse = np.argmax(partial_y_train,axis=1)
y_val_sparse = np.argmax(y_val,axis=1)
print(len(partial_y_train_sparse),len(y_val_sparse))
7982 1000
y_val_sparse.shape
(1000,)
model.fit(partial_x_train,
partial_y_train_sparse,
epochs=6,
batch_size=512,
validation_data=(x_val, y_val_sparse))
Train on 7982 samples, validate on 1000 samples
Epoch 1/6
7982/7982 [==============================] - 1s 121us/step - loss: 2.5698 - acc: 0.5130 - val_loss: 1.7008 - val_acc: 0.6410
Epoch 2/6
7982/7982 [==============================] - 1s 70us/step - loss: 1.3734 - acc: 0.7120 - val_loss: 1.3135 - val_acc: 0.7300
Epoch 3/6
7982/7982 [==============================] - 1s 71us/step - loss: 1.0269 - acc: 0.7860 - val_loss: 1.1446 - val_acc: 0.7630
Epoch 4/6
7982/7982 [==============================] - 1s 72us/step - loss: 0.8019 - acc: 0.8336 - val_loss: 1.0724 - val_acc: 0.7620
Epoch 5/6
7982/7982 [==============================] - 1s 70us/step - loss: 0.6437 - acc: 0.8664 - val_loss: 1.0476 - val_acc: 0.7700
Epoch 6/6
7982/7982 [==============================] - 1s 70us/step - loss: 0.5111 - acc: 0.8966 - val_loss: 0.9534 - val_acc: 0.8040
<keras.callbacks.History at 0x18f01459f28>
results = model.evaluate(x_test, test_labels)
2246/2246 [==============================] - 0s 107us/step
results
[0.9895836060745633, 0.780498664345151]
multi classfication 에서, 제일 중요한 것은 마지막 출력이 46차원이기 때문에, 중간 hidden layer 노드가 충분히 갯수를 가져야 한다.
그렇지 않으면 병목현상이 있기 때문이다.
마지막 출력이 46차원이기 때문에 중간층의 히든 유닛이 46개보다 많이 적어서는 안 됩니다.
실제로 hidden layer 덴스를 줄여서 해보게 되면, 검증 정확도의 최고 값은 약 71%로 8% 정도 감소되었습니다. 이런 손실의 대부분 원인은 많은 정보(46개 클래스의 분할 초평면을 복원하기에 충분한 정보)를 중간층의 저차원 표현 공간으로 압축하려고 했기 때문입니다. 이 네트워크는 필요한 정보 대부분을 4차원 표현 안에 구겨 넣었지만 전부는 넣지 못했습니다.
model.add(layers.Dense(64, activation=’relu’, input_shape=(10000,)))
model.add(layers.Dense(4, activation=’relu’))
model.add(layers.Dense(46, activation=’softmax’))
Comments