
Text Analyis Basic using Scikit-Learn (python 텍스트 분석 01)
‘Introduction to Machine Learning with Python - Capter 7’ 과 ‘케라스 창시자에게 배우는 딥러닝’ 을 읽고, 혼자 정리한 것임을 밝힘
Text 분석 개요
크게, Python 에서는 일반 sckit-learn library 를 활용한 text분석과 Neural Net 를 활용한 text 분석 2개를 사용할 수 있다.
요즘은 특히 RNN 네트워크를 통한 NN 방식이 더 각광받고 있다. 특히 NN 방식은 Keras library를 대중적으로 많이 사용한다.
그러나, 텍스트 분석은 어떤 방식으로도 이뤄질수 있고, Text 분서과정에 매우 중요한 전처리 (Token화 - 어휘사전 구축 - 인코딩) 과정과, 데이터셋이 어떤게 구성되는지를 아는 것은 중요하다.
따라서, 여기서는 어떤식으로 이루지는지 기본적인 내용을 답습할 필요가 있다.
(https://www.kaggle.com/c/word2vec-nlp-tutorial)
## 라이브러리 로드
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
%matplotlib inline
# 시각화 결과가 선명하게 표시되도록
%config InlineBackend.figure_format = 'retina'
시각화를 위한 한글폰트 설정
# Window 한글폰트 설정
# plt.rc("font", family="Malgun Gothic")
# Mac 한글폰트 설정
plt.rc("font", family="AppleGothic")
plt.rc('axes', unicode_minus=False)
IMDB 데이터 불러와서 활용하기
일단, 공통적으로 사용할 데이터셋으로 keras 내부 IMDB 를 불러온다.
from keras.datasets import imdb
Using TensorFlow backend.
# (train_x,train_y),(test_x,text_y) = imdb.load_data(num_words=10000) ## 가장 자주 사용하는 단어수를 10000 개로 제한한다는 뜻
(train_x,train_y),(test_x,text_y) = imdb.load_data() ## 원본을 그대로 활용해보다.
print(type(train_x),train_x.shape,test_x.shape)
print("ndim_train_x :",train_x.ndim)
print("ndim_test_x :",test_x.ndim)
print(train_x[3][0:3])
<class 'numpy.ndarray'> (25000,) (25000,)
ndim_train_x : 1
ndim_test_x : 1
[1, 4, 18609]
np.bincount(train_y)
array([12500, 12500], dtype=int64)
keras 로 불러오니, numpy matrix 구조이다. ndim 은 모두 1이다. 예제를 따라하기 위해서, 데이터 구조를 조금 만지면,
(원 데이터는 vector 화 되어 있지 않으니깐, 원본으로 되돌리면 가능하지 않을까란 생각에 시도해본다.)
결론부터 말하자면, keras.datasets 의 IMDB 데이터는 이미 기본정제가 되어 있기때문에 좀더 상세하게 해보기에는 적합하지 않다.
밑의 코드는 참고만 하길 바란다.
참고코드
word_index = imdb.get_word_index()
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
decode_review = ‘ ‘.join([reverse_word_index.get(i-3,’?’) for i in train_x[0]])
decode_review
이미, 어느정도 정제되어 있어서….완벽한 예제라고 하기 어렵다….완전히 다시 다운받아서 해본다
## 다시 인터넷에서 다운 받고나서
from sklearn.datasets import load_files
reviews_train = load_files("D:/★2020_ML_DL_Project/Alchemy/dataset/aclImdb/train/")
text_train,y_train = reviews_train.data,reviews_train.target
%time
Wall time: 0 ns
print(type(text_train[0]))
print(text_train[0])
<class 'bytes'>
b"Zero Day leads you to think, even re-think why two boys/young men would do what they did - commit mutual suicide via slaughtering their classmates. It captures what must be beyond a bizarre mode of being for two humans who have decided to withdraw from common civility in order to define their own/mutual world via coupled destruction.<br /><br />It is not a perfect movie but given what money/time the filmmaker and actors had - it is a remarkable product. In terms of explaining the motives and actions of the two young suicide/murderers it is better than 'Elephant' - in terms of being a film that gets under our 'rationalistic' skin it is a far, far better film than almost anything you are likely to see. <br /><br />Flawed but honest with a terrible honesty."
reviews_test = load_files("D:/★2020_ML_DL_Project/Alchemy/dataset/aclImdb/test/")
text_test,y_test = reviews_test.data,reviews_test.target
%time
Wall time: 0 ns
## <br /> tag 제거한다. 데이터 정제과정
text_train = [doc.replace(b"<br />",b" ") for doc in text_train]
text_test = [doc.replace(b"<br />",b" ") for doc in text_test]
print("text_train.shape :",len(text_train))
print("text_test.shape :",len(text_test))
text_train.shape : 25000
text_test.shape : 25000
Sckit-learn - CounterVectorizer 연습하기
Introduction to Machine Learning with Python 예제를 활용했음을 미리 밝힌다.!
any_words = ["The foll doth think he is wife","but the wise man knows himself to be a fool"]
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer() ## (Token화 - 어휘사전 구축 - 인코딩) 기본적인 기능을 수행하는 library 이다.
vect.fit(any_words)
## 잊지말고 기억해야 할것은 어떤 라이브러리 이든 (Token화 - 어휘사전 구축 - 인코딩) 은 기본적으로 갖추어야 할 매우 중요한 기능 = 소양 이다.
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
print("어휘 사전의 크기: {}".format(len(vect.vocabulary_)))
print("어휘 사전의 내용:\n {}".format(vect.vocabulary_))
어휘 사전의 크기: 15
어휘 사전의 내용:
{'the': 10, 'foll': 3, 'doth': 2, 'think': 11, 'he': 5, 'is': 7, 'wife': 13, 'but': 1, 'wise': 14, 'man': 9, 'knows': 8, 'himself': 6, 'to': 12, 'be': 0, 'fool': 4}
위의 결과를 보면 알 수 있듯이, 가장 기본적인 정규식으로, Token 화 와 어휘사전을 구축했다. 이제 transform 을 하면 ‘인코딩’ 이 완성된다.
물론, 현재 코드에서는 Token 화 (“\b\w\w+\b”) 와 어휘사전 구축을 기본 default 로 했으나, 얼마든지 customizing 해서 바꿀 수 있다는 점이 중요하다.
bag_of_words = vect.transform(any_words)
print("type : {}".format(repr(bag_of_words)))
print(type(bag_of_words))
type : <2x15 sparse matrix of type '<class 'numpy.int64'>'
with 16 stored elements in Compressed Sparse Row format>
<class 'scipy.sparse.csr.csr_matrix'>
보시다시피, transform은 sciy.sparse 희소행렬을 return 해준다.
본격적으로 IMDB 데이터에 적용해보면,
vect = CountVectorizer().fit(text_train) ## fit 할때, Tocken 화와 어휘사전 구축이 이루어진다.
X_train = vect.transform(text_train) ## encoding 을 했다.
feature_names = vect.get_feature_names()
type(feature_names)
list
print("특성 개수: {}".format(len(feature_names)))
print("처음 20개 특성:\n{}".format(feature_names[:20]))
print("20010에서 20030까지 특성:\n{}".format(feature_names[20010:20030]))
print("매 2000번째 특성:\n{}".format(feature_names[::2000]))
특성 개수: 74849
처음 20개 특성:
['00', '000', '0000000000001', '00001', '00015', '000s', '001', '003830', '006', '007', '0079', '0080', '0083', '0093638', '00am', '00pm', '00s', '01', '01pm', '02']
20010에서 20030까지 특성:
['dratted', 'draub', 'draught', 'draughts', 'draughtswoman', 'draw', 'drawback', 'drawbacks', 'drawer', 'drawers', 'drawing', 'drawings', 'drawl', 'drawled', 'drawling', 'drawn', 'draws', 'draza', 'dre', 'drea']
매 2000번째 특성:
['00', 'aesir', 'aquarian', 'barking', 'blustering', 'bête', 'chicanery', 'condensing', 'cunning', 'detox', 'draper', 'enshrined', 'favorit', 'freezer', 'goldman', 'hasan', 'huitieme', 'intelligible', 'kantrowitz', 'lawful', 'maars', 'megalunged', 'mostey', 'norrland', 'padilla', 'pincher', 'promisingly', 'receptionist', 'rivals', 'schnaas', 'shunning', 'sparse', 'subset', 'temptations', 'treatises', 'unproven', 'walkman', 'xylophonist']
어휘사전을 보면, 쓸데없는 단어들도 많이 들어가 있음을 알수 있다.
이런 것들은 안에 있는 parameter min_df , max_df , 불용어 사전등을 활용해서, 최대한 핵심적인 내용으로 어휘사전을 꾸미거나,
차용할수 있다.
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression ## 통상 0,1 로 이루어진 one-hot 성 값들을 가지는 vector 들은 logistic 에 매우 유용하다는 연구가 있다.
scores = cross_val_score(LogisticRegression(solver="newton-cg"), X_train, y_train, cv=5)
print("크로스 밸리데이션 평균 점수: {:.2f}".format(np.mean(scores)))
크로스 밸리데이션 평균 점수: 0.88
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10]}
grid = GridSearchCV(LogisticRegression(solver="newton-cg"), param_grid, cv=5)
grid.fit(X_train, y_train)
print("최상의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
print("최적의 매개변수: ", grid.best_params_)
최상의 크로스 밸리데이션 점수: 0.89
최적의 매개변수: {'C': 0.1}
X_test = vect.transform(text_test)
print("테스트 점수: {:.2f}".format(grid.score(X_test, y_test)))
테스트 점수: 0.88
min_df=5 는 최소 5개 샘플(=문단) 에서 등장하는 것이 의미있는 단어로 판단해서, 어휘사전을 만든다는 의미이다.
당연히 vector 길이가 짧아진다 74849 –> 27271
vect = CountVectorizer(min_df=5).fit(text_train)
X_train = vect.transform(text_train)
print("min_df로 제한한 X_train: {}".format(repr(X_train)))
min_df로 제한한 X_train: <25000x27271 sparse matrix of type '<class 'numpy.int64'>'
with 3354014 stored elements in Compressed Sparse Row format>
feature_names = vect.get_feature_names()
print("First 50 features:\n{}".format(feature_names[:50]))
print("Features 20010 to 20030:\n{}".format(feature_names[20010:20030]))
print("Every 700th feature:\n{}".format(feature_names[::700]))
First 50 features:
['00', '000', '007', '00s', '01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '100', '1000', '100th', '101', '102', '103', '104', '105', '107', '108', '10s', '10th', '11', '110', '112', '116', '117', '11th', '12', '120', '12th', '13', '135', '13th', '14', '140', '14th', '15', '150', '15th', '16', '160', '1600', '16mm', '16s', '16th']
Features 20010 to 20030:
['repentance', 'repercussions', 'repertoire', 'repetition', 'repetitions', 'repetitious', 'repetitive', 'rephrase', 'replace', 'replaced', 'replacement', 'replaces', 'replacing', 'replay', 'replayable', 'replayed', 'replaying', 'replays', 'replete', 'replica']
Every 700th feature:
['00', 'affections', 'appropriately', 'barbra', 'blurbs', 'butchered', 'cheese', 'commitment', 'courts', 'deconstructed', 'disgraceful', 'dvds', 'eschews', 'fell', 'freezer', 'goriest', 'hauser', 'hungary', 'insinuate', 'juggle', 'leering', 'maelstrom', 'messiah', 'music', 'occasional', 'parking', 'pleasantville', 'pronunciation', 'recipient', 'reviews', 'sas', 'shea', 'sneers', 'steiger', 'swastika', 'thrusting', 'tvs', 'vampyre', 'westerns']
grid = GridSearchCV(LogisticRegression(solver="newton-cg"), param_grid, cv=5)
grid.fit(X_train, y_train)
print("최적의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
최적의 크로스 밸리데이션 점수: 0.89
불용어
의미없는 단어를 제거하는 또 다른 방법은 너무 빈번하여 유용하지 않는 단어를 제거하는 것이다.
- 언어별 불용어 목록 사용하기
- 자주나타는 단어 제외하기
## 영어의 불용어 사용하기
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
print("불용어 개수: {}".format(len(ENGLISH_STOP_WORDS)))
print("매 10번째 불용어:\n{}".format(list(ENGLISH_STOP_WORDS)[::10]))
불용어 개수: 318
매 10번째 불용어:
['latterly', 'keep', 'detail', 'are', 'amoungst', 'beforehand', 'itself', 'ourselves', 'no', 'seems', 'cant', 'nevertheless', 'made', 'yourself', 'toward', 'wherever', 'side', 'you', 'their', 'some', 'as', 'above', 'eight', 'seemed', 'few', 'during', 'out', 'about', 'have', 'do', 'co', 'hence']
# stop_words="english"라고 지정하면 내장된 불용어를 사용합니다.
# 내장된 불용어에 추가할 수도 있고 자신만의 목록을 사용할 수도 있습니다.
vect = CountVectorizer(min_df=5, stop_words="english").fit(text_train)
X_train = vect.transform(text_train)
print("불용어가 제거된 X_train:\n{}".format(repr(X_train)))
불용어가 제거된 X_train:
<25000x26966 sparse matrix of type '<class 'numpy.int64'>'
with 2149958 stored elements in Compressed Sparse Row format>
grid = GridSearchCV(LogisticRegression(solver="newton-cg"), param_grid, cv=5)
grid.fit(X_train, y_train)
print("최상의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
최상의 크로스 밸리데이션 점수: 0.88
# from sklearn.pipeline import make_pipeline
# pipe = make_pipeline(CountVectorizer(), LogisticRegression(solver="newton-cg"))
# param_grid = {'countvectorizer__max_df': [100, 1000, 10000, 20000], 'logisticregression__C': [0.001, 0.01, 0.1, 1, 10]}
# grid = GridSearchCV(pipe, param_grid, cv=5)
# grid.fit(text_train, y_train)
# print("최상의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
# print(grid.best_params_)
너무 오래 걸려서, 매번 GridSearch 를 하기에는 무리다. 넘어간다.
tf–idf로 데이터 스케일 변경
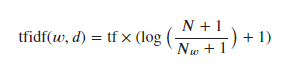
중요하지 않아 보이는 특성을 제외하는 대신, 얼마나 의미 있는 특성인지를 계산해서 스케일을 조정하는 방식이 있다.
이중 널리 알려진 방법이 tf-idf (term frequency - inverse document frequency) 이다.
- 다른 문서보다 특정 문서에 자주 나타나는 단어에 가중치를 준다. 이는 그 자주나타나는 단어가 그 문서(문단)을 잘 설명하고 있다는 가정에서 출발했기 때문
- TfidfVectorizer 는 CounterVectorizer 의 서브클래스로, CounterVectorizer가 만든 희소 행렬을 입력받아 변환한다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import make_pipeline
tfidf_vect = TfidfVectorizer(min_df=5)
tfidf_vect.fit(text_train)
X_train_tfidf = tfidf_vect.transform(text_train) ## encoding 을 했다.
print(type(X_train))
<class 'scipy.sparse.csr.csr_matrix'>
동일한 type 이 return 되는 것을 알 수 있다. 헌데, CounterVectorizer 에서 가중치 개념을 좀 더 더한것이라는데, 어떤 차이 가 있는지 확인해보다 Start
# 다시 변환시킴~
vector_00 = CountVectorizer(min_df=5).fit(text_train)
X_train = vector_00.transform(text_train)
tt = X_train[11].toarray().copy()
print(len(tt[0]),tt.shape)
np.argmax(tt)
27271 (1, 27271)
24346
rslt = []
for i in range(10):
r = np.argmax(tt[0])
rslt.append(r)
tt[0][r] = 0
# tt = np.delete(tt,r)
## 나름 countervector 에서 큰 값 순으로, index 를 골라봄
rslt
[24346, 12985, 24634, 1143, 12253, 12952, 12993, 26418, 27155, 9588]
feature_names = vector_00.get_feature_names()
type(feature_names)
list
for idx in rslt:
print(feature_names[idx],": ",X_train[11].toarray()[0][idx]) ##
the : 13
it : 4
to : 4
and : 3
in : 3
is : 3
its : 3
was : 3
you : 3
for : 2
feature_names_tfidf = tfidf_vect.get_feature_names()
type(feature_names_tfidf)
revers_dict_feature_name = {}
for i,val in enumerate(feature_names_tfidf):
if val not in revers_dict_feature_name.keys():
revers_dict_feature_name[val] = i
word = ['the','it','to','and','in','its','was','you','for']
for key in word:
print("key : {}".format(key),revers_dict_feature_name[key])
val = revers_dict_feature_name[key]
print(X_train_tfidf.toarray()[11][val])
print("="*10)
key : the 24346
0.2595587007756212
==========
key : it 12985
0.08831450280318394
==========
key : to 24634
0.08419067316701101
==========
key : and 1143
0.061424636510561285
==========
key : in 12253
0.06689258070230526
==========
key : its 12993
0.15264998200500912
==========
key : was 26418
0.08530485667596949
==========
key : you 27155
0.09543270798037227
==========
key : for 9588
0.05286573956046148
==========
보시다시피, scale 이 조정되었다.
동일한 type 이 return 되는 것을 알 수 있다. 헌데, CounterVectorizer 에서 가중치 개념을 좀 더 더한것이라는데, 어떤 차이 가 있는지 확인해보다 End
## 진행
pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression(solver="newton-cg"))
param_grid = {'logisticregression__C': [0.001, 0.01]}
grid = GridSearchCV(pipe, param_grid, cv=4)
grid.fit(text_train, y_train)
print("최상의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
최상의 크로스 밸리데이션 점수: 0.80
vectorizer = grid.best_estimator_.named_steps["tfidfvectorizer"]
# 훈련 데이터셋을 변환합니다
X_train = vectorizer.transform(text_train)
# 특성별로 가장 큰 값을 찾습니다
max_value = X_train.max(axis=0).toarray().ravel() ## X_train.toarray().max(axis=0).ravel() 이거랑 결과는 똑같다.
len(max_value)
27271
sorted_by_tfidf = max_value.argsort()
# 특성 이름을 구합니다
feature_names = np.array(vectorizer.get_feature_names())
print("가장 낮은 tfidf를 가진 특성:\n{}".format(
feature_names[sorted_by_tfidf[:20]]))
print("가장 높은 tfidf를 가진 특성: \n{}".format(
feature_names[sorted_by_tfidf[-20:]]))
가장 낮은 tfidf를 가진 특성:
['suplexes' 'gauche' 'hypocrites' 'oncoming' 'songwriting' 'galadriel'
'emerald' 'mclaughlin' 'sylvain' 'oversee' 'cataclysmic' 'pressuring'
'uphold' 'thieving' 'inconsiderate' 'ware' 'denim' 'reverting' 'booed'
'spacious']
가장 높은 tfidf를 가진 특성:
['gadget' 'sucks' 'zatoichi' 'demons' 'lennon' 'bye' 'dev' 'weller'
'sasquatch' 'botched' 'xica' 'darkman' 'woo' 'casper' 'doodlebops'
'smallville' 'wei' 'scanners' 'steve' 'pokemon']
sorted_by_idf = np.argsort(vectorizer.idf_)
print("가장 낮은 idf를 가진 특성:\n{}".format(
feature_names[sorted_by_idf[:100]]))
가장 낮은 idf를 가진 특성:
['the' 'and' 'of' 'to' 'this' 'is' 'it' 'in' 'that' 'but' 'for' 'with'
'was' 'as' 'on' 'movie' 'not' 'have' 'one' 'be' 'film' 'are' 'you' 'all'
'at' 'an' 'by' 'so' 'from' 'like' 'who' 'they' 'there' 'if' 'his' 'out'
'just' 'about' 'he' 'or' 'has' 'what' 'some' 'good' 'can' 'more' 'when'
'time' 'up' 'very' 'even' 'only' 'no' 'would' 'my' 'see' 'really' 'story'
'which' 'well' 'had' 'me' 'than' 'much' 'their' 'get' 'were' 'other'
'been' 'do' 'most' 'don' 'her' 'also' 'into' 'first' 'made' 'how' 'great'
'because' 'will' 'people' 'make' 'way' 'could' 'we' 'bad' 'after' 'any'
'too' 'then' 'them' 'she' 'watch' 'think' 'acting' 'movies' 'seen' 'its'
'him']
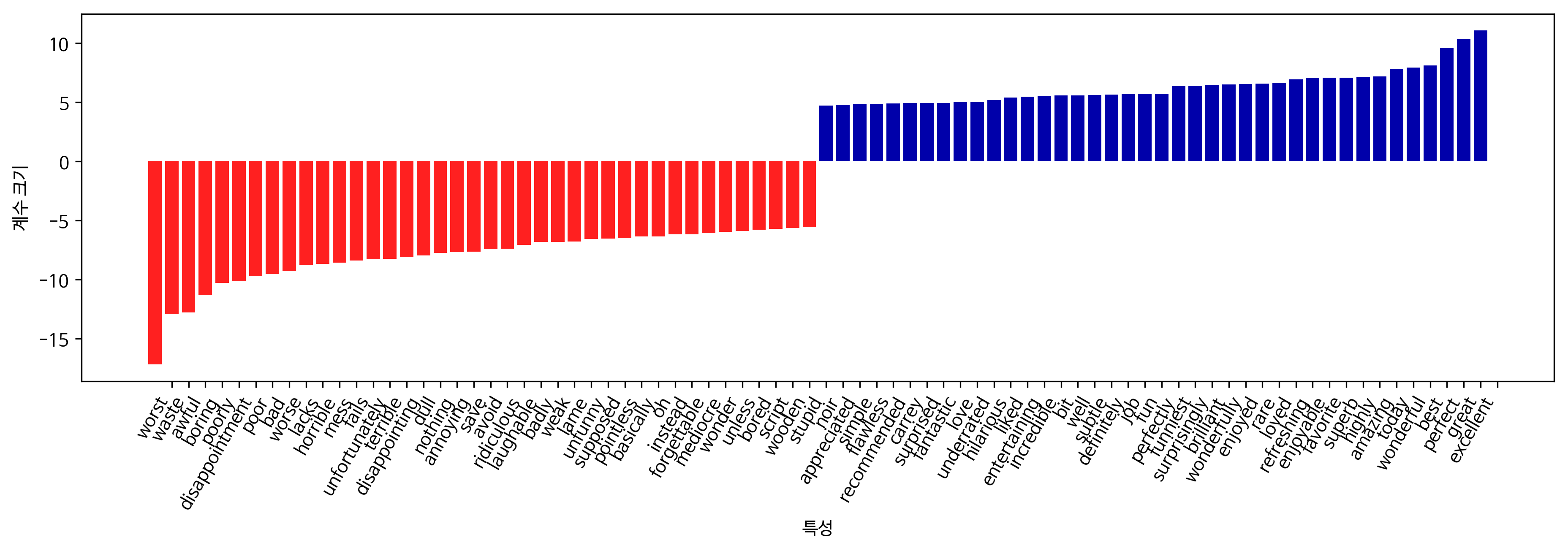
모델 계수 조사
grid.best_estimator_.named_steps["logisticregression"].coef_
array([[-0.00952316, -0.01816299, 0.00369091, ..., -0.00399722,
-0.00423328, 0.00082527]])
mglearn.tools.visualize_coefficients(
grid.best_estimator_.named_steps["logisticregression"].coef_[0],
feature_names, n_top_features=40)
Comments