
Text Analyis Basic using Scikit-Learn (python 텍스트 분석 02)
여기서는 우선, TF-IDF 에 대한 내용을 한번 더 상세히 다루고, n-gram , KoNLPy 순서로 진행한다.
(https://www.kaggle.com/c/word2vec-nlp-tutorial)
참고로 TF-IDF 정리는 wikidocs 의 “딥 러닝을 이용한 자연어 처리 입문” 을 참고했다. 텍스트 분석용으로 한국어 책으로 훌륭하다.
## 라이브러리 로드
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
%matplotlib inline
# 시각화 결과가 선명하게 표시되도록
%config InlineBackend.figure_format = 'retina'
# "D:\★2020_ML_DL_Project\Alchemy\DL_Area"
import mglearn ## 별도 https://github.com/rickiepark/introduction_to_ml_with_python 의 library
시각화를 위한 한글폰트 설정
# Window 한글폰트 설정
# plt.rc("font", family="Malgun Gothic")
# Mac 한글폰트 설정
plt.rc("font", family="AppleGothic")
plt.rc('axes', unicode_minus=False)
IMDB 데이터 불러와서 활용하기
이미, 어느정도 정제되어 있어서….완벽한 예제라고 하기 어렵다….완전히 다시 다운받아서 해본다
## 다시 인터넷에서 다운 받고나서
from sklearn.datasets import load_files
reviews_train = load_files("D:/★2020_ML_DL_Project/Alchemy/dataset/aclImdb/train/")
text_train,y_train = reviews_train.data,reviews_train.target
%time
Wall time: 0 ns
print(type(text_train[0]))
print(text_train[0])
<class 'bytes'>
b"Zero Day leads you to think, even re-think why two boys/young men would do what they did - commit mutual suicide via slaughtering their classmates. It captures what must be beyond a bizarre mode of being for two humans who have decided to withdraw from common civility in order to define their own/mutual world via coupled destruction.<br /><br />It is not a perfect movie but given what money/time the filmmaker and actors had - it is a remarkable product. In terms of explaining the motives and actions of the two young suicide/murderers it is better than 'Elephant' - in terms of being a film that gets under our 'rationalistic' skin it is a far, far better film than almost anything you are likely to see. <br /><br />Flawed but honest with a terrible honesty."
reviews_test = load_files("D:/★2020_ML_DL_Project/Alchemy/dataset/aclImdb/test/")
text_test,y_test = reviews_test.data,reviews_test.target
%time
Wall time: 0 ns
## <br /> tag 제거한다. 데이터 정제과정
text_train = [doc.replace(b"<br />",b" ") for doc in text_train]
text_test = [doc.replace(b"<br />",b" ") for doc in text_test]
print("text_train.shape :",len(text_train))
print("text_test.shape :",len(text_test))
text_train.shape : 25000
text_test.shape : 25000
TF-IDF 집중 연습하기
wikidocs 책을 바탕으로 했음을 밝힌다.!! (상단의 “딥러닝을 이용한 자연어 처리 입문” 설명을 차용)
TF-IDF 를 통해서 나오는 값은 각각의 TF,IDF term 을 구한후, 곱하는 것임
- TF-IDF(단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법입니다. 사용 방법은 우선 DTM을 만든 후, TF-IDF 가중치를 부여합니다.
※ DTM (Document Term Matrix) BOW 를 단어 빈도수 count Matrix로 표현한것
TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있습니다.
TF-IDF는 TF와 IDF를 곱한 값을 의미하는데 이를 식으로 표현해보겠습니다. 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 TF, DF, IDF는 각각 다음과 같이 정의할 수 있습니다.
1-(1) tf(d,t)
특정 문서 d에서의 특정 단어 t의 등장 횟수.
TF는 앞에서 배운 DTM의 예제에서 각 단어들이 가진 값들입니다. DTM이 각 문서에서의 각 단어의 등장 빈도를 나타내는 값이었기 때문입니다.
1-(2) df(t)
특정 단어 t가 등장한 문서의 수.
여기서 특정 단어가 각 문서, 또는 문서들에서 몇 번 등장했는지는 중요치 않으며 오직 특정 단어 t가 등장한 문서의 수에만 관심을 가집니다. 앞서 배운 DTM에서 바나나는 문서2와 문서3에서 등장했습니다. 이 경우, 바나나의 df는 2입니다. 문서3에서 바나나가 두 번 등장했지만, 그것은 중요한 게 아닙니다. 심지어 바나나란 단어가 문서2에서 100번 등장했고, 문서3에서 200번 등장했다고 하더라도 바나나의 df는 2가 됩니다.
1-(3) idf(d, t)
df(t)에 반비례하는 수.
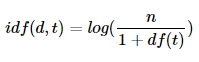
DF라는 이름을 보고 DF의 역수가 아닐까 생각했다면, IDF는 DF의 역수를 취하고 싶은 것이 맞습니다. 그런데 log와 분모에 1을 더해주는 식에 의아하실 수 있습니다. log를 사용하지 않았을 때, IDF를 DF의 역수(n/df(t)라는 식)로 사용한다면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커지게 됩니다. 그렇기 때문에 log를 사용합니다.
IDF 값이 낮다는 것은 자주 등장하기 때문에, 중요하지 않다고 나오는 뜻이다
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단합니다.
TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것입니다.
즉, the나 a와 같이 불용어의 경우에는 모든 문서에 자주 등장하기 마련이기 때문에 자연스럽게 불용어의 TF-IDF의 값은 다른 단어의 TF-IDF에 비해서 낮아지게 됩니다.
실제 수식으로 확인해보자
import pandas as pd # 데이터프레임 사용을 위해
from math import log # IDF 계산을 위해
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
vocab = list(set(w for doc in docs for w in doc.split())) ## 토근화 시킨, 어휘사전을 만드는 과정
vocab.sort()
print(type(vocab))
vocab
<class 'list'>
['과일이', '길고', '노란', '먹고', '바나나', '사과', '싶은', '저는', '좋아요']
N = len(docs) # 총 문서의 수
def tf(t, d): ## 특정 문서 d에서의 특정 단어 t의 등장 횟수.
return d.count(t)
def idf(t):
df = 0 ## 이렇게 설정하면, True 값에 대해서, 1씩 더하게 된다.
for doc in docs:
df += t in doc ## df : 특정 단어 t가 등장한 문서의 수.
return log(N/(df + 1)) ## df(t)에 반비례하는 수.
def tfidf(t, d):
return tf(t,d)* idf(t)
우선, df 값. == 그냥 VectorCounter() 함수 사용시 == DCM 구하기
print("총문서의 수",N)
result = []
for i in range(N): # 각 문서에 대해서 아래 명령을 수행
result.append([])
d = docs[i]
print("{}번째문서 : {}".format(i,d))
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tf(t, d))
# print(result[-1])
tf_ = pd.DataFrame(result, columns = vocab)
tf_
총문서의 수 4
0번째문서 : 먹고 싶은 사과
1번째문서 : 먹고 싶은 바나나
2번째문서 : 길고 노란 바나나 바나나
3번째문서 : 저는 과일이 좋아요
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
IDF 값 구하기
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
# print(result)
idf_ = pd.DataFrame(result, index = vocab, columns = ["IDF"])
idf_
| IDF | |
|---|---|
| 과일이 | 0.693147 |
| 길고 | 0.693147 |
| 노란 | 0.693147 |
| 먹고 | 0.287682 |
| 바나나 | 0.287682 |
| 사과 | 0.693147 |
| 싶은 | 0.287682 |
| 저는 | 0.693147 |
| 좋아요 | 0.693147 |
TF_IDF 행렬 출력
result = []
for i in range(N):
result.append([])
d = docs[i]
print("{}번째문서 : {}".format(i,d))
for j in range(len(vocab)):
t = vocab[j]
if i == 0:
print("{}번째문서 : {}번째 단어".format(i,j))
result[-1].append(tfidf(t,d))
if i == 0:
print("Logic검토 tf(t, d):{}, idf(t):{}".format(tf(t, d),idf(t)))
print(result[-1])
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_
0번째문서 : 먹고 싶은 사과
0번째문서 : 0번째 단어
Logic검토 tf(t, d):0, idf(t):0.6931471805599453
[0.0]
0번째문서 : 1번째 단어
Logic검토 tf(t, d):0, idf(t):0.6931471805599453
[0.0, 0.0]
0번째문서 : 2번째 단어
Logic검토 tf(t, d):0, idf(t):0.6931471805599453
[0.0, 0.0, 0.0]
0번째문서 : 3번째 단어
Logic검토 tf(t, d):1, idf(t):0.28768207245178085
[0.0, 0.0, 0.0, 0.28768207245178085]
0번째문서 : 4번째 단어
Logic검토 tf(t, d):0, idf(t):0.28768207245178085
[0.0, 0.0, 0.0, 0.28768207245178085, 0.0]
0번째문서 : 5번째 단어
Logic검토 tf(t, d):1, idf(t):0.6931471805599453
[0.0, 0.0, 0.0, 0.28768207245178085, 0.0, 0.6931471805599453]
0번째문서 : 6번째 단어
Logic검토 tf(t, d):1, idf(t):0.28768207245178085
[0.0, 0.0, 0.0, 0.28768207245178085, 0.0, 0.6931471805599453, 0.28768207245178085]
0번째문서 : 7번째 단어
Logic검토 tf(t, d):0, idf(t):0.6931471805599453
[0.0, 0.0, 0.0, 0.28768207245178085, 0.0, 0.6931471805599453, 0.28768207245178085, 0.0]
0번째문서 : 8번째 단어
Logic검토 tf(t, d):0, idf(t):0.6931471805599453
[0.0, 0.0, 0.0, 0.28768207245178085, 0.0, 0.6931471805599453, 0.28768207245178085, 0.0, 0.0]
1번째문서 : 먹고 싶은 바나나
2번째문서 : 길고 노란 바나나 바나나
3번째문서 : 저는 과일이 좋아요
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.000000 | 0.000000 | 0.287682 | 0.000000 | 0.693147 | 0.287682 | 0.000000 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 0.000000 | 0.287682 | 0.287682 | 0.000000 | 0.287682 | 0.000000 | 0.000000 |
| 2 | 0.000000 | 0.693147 | 0.693147 | 0.000000 | 0.575364 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 3 | 0.693147 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.693147 | 0.693147 |
## 직접곱셈으로 보여주기
ttarr = idf_.values
rslt_arr = np.zeros((9,9),dtype=float)
# print(rslt_arr)
for i in range(len(ttarr)):
for j in range(len(ttarr)):
if i == j:
rslt_arr[i,j] = ttarr[i][0]
np.set_printoptions(linewidth=np.inf)
np.dot(tf_.values,rslt_arr)
array([[0. , 0. , 0. , 0.28768207, 0. , 0.69314718, 0.28768207, 0. , 0. ],
[0. , 0. , 0. , 0.28768207, 0.28768207, 0. , 0.28768207, 0. , 0. ],
[0. , 0.69314718, 0.69314718, 0. , 0.57536414, 0. , 0. , 0. , 0. ],
[0.69314718, 0. , 0. , 0. , 0. , 0. , 0. , 0.69314718, 0.69314718]])
tfidf 는 결국 tf 와 idf 값을 곱한것이니, 행력 shape 을 맞추어 주고 나서, 곱하는 것과 같다.
사이킷런을 이용한 DTM과 TF-IDF 실습
from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
print(vector.fit_transform(docs).toarray()) # 코퍼스로부터 각 단어의 빈도 수를 기록한다.
print(vector.vocabulary_) # 각 단어의 인덱스가 어떻게 부여되었는지를 보여준다.
[[0 0 0 1 0 1 1 0 0]
[0 0 0 1 1 0 1 0 0]
[0 1 1 0 2 0 0 0 0]
[1 0 0 0 0 0 0 1 1]]
{'먹고': 3, '싶은': 6, '사과': 5, '바나나': 4, '길고': 1, '노란': 2, '저는': 7, '과일이': 0, '좋아요': 8}
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfv = TfidfVectorizer().fit(docs)
print(tfidfv.transform(docs).toarray())
print(tfidfv.vocabulary_)
[[0. 0. 0. 0.52640543 0. 0.66767854 0.52640543 0. 0. ]
[0. 0. 0. 0.57735027 0.57735027 0. 0.57735027 0. 0. ]
[0. 0.47212003 0.47212003 0. 0.7444497 0. 0. 0. 0. ]
[0.57735027 0. 0. 0. 0. 0. 0. 0.57735027 0.57735027]]
{'먹고': 3, '싶은': 6, '사과': 5, '바나나': 4, '길고': 1, '노란': 2, '저는': 7, '과일이': 0, '좋아요': 8}
TF_IDF 값이 다른 이유는 sckit-learn 에서는 수식이 약간 다르다. L2 정규화 Term 을 이용하기 때문이며,
sckit-learn 의 수식은 Basic 01 을 참고하기를~
BOW 의 발전 (n-gram)
Bag Of Word 의 대표적인 단점은 단어의 순서가 무시된다는 점이 있다.
이에, unigram(1개씩), bigram(2개씩), trigram(3개씩) 연속되는 단어를 묶어서, 표현하는 기법이 존재한다.
예를 들어 ex> “it’s bad, not good at all” vs “it’s good, not bad at all” 의 표현은 기본 BOW (unigram 방식) 일때는 똑긑은 의미로 인식해버리기 때문이다.
bards_words =["The fool doth think he is wise,",
"but the wise man knows himself to be a fool"]
print("bards_words:\n{}".format(bards_words))
bards_words:
['The fool doth think he is wise,', 'but the wise man knows himself to be a fool']
cv = CountVectorizer(ngram_range=(1, 1)).fit(bards_words)
print("어휘 사전 크기: {}".format(len(cv.vocabulary_)))
print("어휘 사전:\n{}".format(cv.get_feature_names()))
어휘 사전 크기: 13
어휘 사전:
['be', 'but', 'doth', 'fool', 'he', 'himself', 'is', 'knows', 'man', 'the', 'think', 'to', 'wise']
cv = CountVectorizer(ngram_range=(2, 2)).fit(bards_words)
print("어휘 사전 크기: {}".format(len(cv.vocabulary_)))
print("어휘 사전:\n{}".format(cv.get_feature_names()))
어휘 사전 크기: 14
어휘 사전:
['be fool', 'but the', 'doth think', 'fool doth', 'he is', 'himself to', 'is wise', 'knows himself', 'man knows', 'the fool', 'the wise', 'think he', 'to be', 'wise man']
print("변환된 데이터 (밀집 배열):\n{}".format(cv.transform(bards_words).toarray()))
변환된 데이터 (밀집 배열):
[[0 0 1 1 1 0 1 0 0 1 0 1 0 0]
[1 1 0 0 0 1 0 1 1 0 1 0 1 1]]
cv = CountVectorizer(ngram_range=(1, 3)).fit(bards_words)
print("어휘 사전 크기: {}".format(len(cv.vocabulary_)))
print("어휘 사전:{}\n".format(cv.get_feature_names()))
어휘 사전 크기: 39
어휘 사전:['be', 'be fool', 'but', 'but the', 'but the wise', 'doth', 'doth think', 'doth think he', 'fool', 'fool doth', 'fool doth think', 'he', 'he is', 'he is wise', 'himself', 'himself to', 'himself to be', 'is', 'is wise', 'knows', 'knows himself', 'knows himself to', 'man', 'man knows', 'man knows himself', 'the', 'the fool', 'the fool doth', 'the wise', 'the wise man', 'think', 'think he', 'think he is', 'to', 'to be', 'to be fool', 'wise', 'wise man', 'wise man knows']
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression())
# 매개변수 조합이 많고 트라이그램이 포함되어 있기 때문에
# 그리드 서치 실행에 시간이 오래 걸립니다
param_grid = {'logisticregression__C': [0.001, 0.01],
"tfidfvectorizer__ngram_range": [(1, 3)]}
grid = GridSearchCV(pipe, param_grid, cv=4)
grid.fit(text_train, y_train)
print("최상의 크로스 밸리데이션 점수: {:.2f}".format(grid.best_score_))
print("최적의 매개변수:\n{}".format(grid.best_params_))
C:\ProgramData\Anaconda3\envs\test\lib\site-packages\sklearn\linear_model\logistic.py:433: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
최상의 크로스 밸리데이션 점수: 0.81
최적의 매개변수:
{'logisticregression__C': 0.01, 'tfidfvectorizer__ngram_range': (1, 3)}
# 그리드 서치에서 테스트 점수를 추출합니다
# scores = grid.cv_results_['mean_test_score'].reshape(-1, 3).T
scores = grid.cv_results_['mean_test_score']
grid.cv_results_.keys()
dict_keys(['mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time', 'param_logisticregression__C', 'param_tfidfvectorizer__ngram_range', 'params', 'split0_test_score', 'split1_test_score', 'split2_test_score', 'split3_test_score', 'mean_test_score', 'std_test_score', 'rank_test_score', 'split0_train_score', 'split1_train_score', 'split2_train_score', 'split3_train_score', 'mean_train_score', 'std_train_score'])
scores ## 0,1 부정 vs 긍정 에 대한 accu 값 확률
array([0.7986, 0.8084])
# 특성 이름과 계수를 추출합니다
vect = grid.best_estimator_.named_steps['tfidfvectorizer']
feature_names = np.array(vect.get_feature_names())
coef = grid.best_estimator_.named_steps['logisticregression'].coef_
mglearn.tools.visualize_coefficients(coef[0], feature_names, n_top_features=40)
plt.ylim(-1, 1)
(-1, 1)
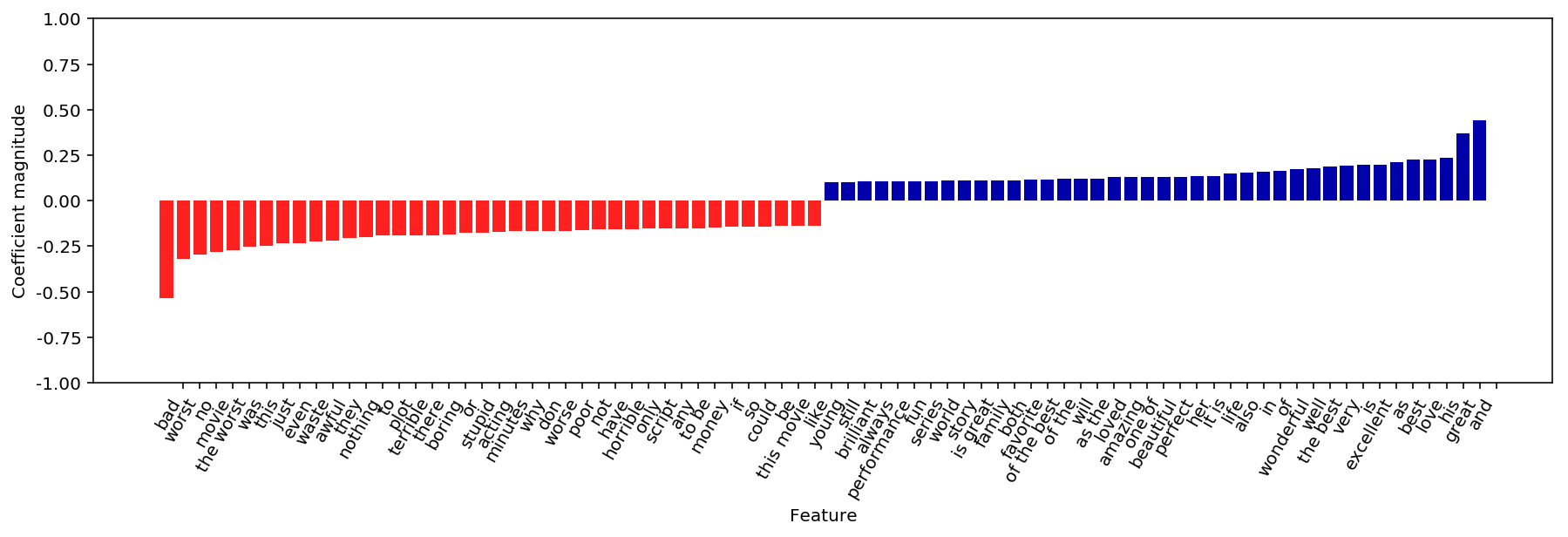
결과는 Basic 01 과 비슷하다.
고급 토큰화, 어간 추출, 표제어 추출
Spacy 영어 모듈을 다운로드 하려면 쉘에서 ‘python -m spacy.en.download all’ 명령을 입력합니다.
토큰화시, 지금까지 본것처럼, 단순히 단어 위주로 토큰화 하는 방법 외에, 좀더 고급진 여러 방법이 있다.
- 어간(stem) : 일일이 어미를 찾아서, 규칙기반으로 토큰화 하는 방법. 쉽게 얘기하면, 영어동사의 단수형, 복수형을 1개로 본다.
- 표제어 추출(lemmatization) : 단어의 알려진 형태사전을 미리 구축해놓고 이를 이용하는 방법
# import spacy ## 표제어 추출
# en_nlp = spacy.load('en_core_web_sm') --> 대신 하기 en_nlp 직접 download
# spacy의 영어 모델을 로드합니다
import en_core_web_sm
en_nlp = en_core_web_sm.load()
import nltk ## 어간추출
import spacy ## 표제어 추출
# nltk의 PorterStemmer 객체를 만듭니다
stemmer = nltk.stem.PorterStemmer()
# spacy의 표제어 추출과 nltk의 어간 추출을 비교하는 함수입니다
def compare_normalization(doc):
# spacy로 문서를 토큰화합니다
doc_spacy = en_nlp(doc)
# spacy로 찾은 표제어를 출력합니다
print("표제어:")
print([token.lemma_ for token in doc_spacy])
# PorterStemmer로 찾은 토큰을 출력합니다
print("어간:")
print([stemmer.stem(token.norm_.lower()) for token in doc_spacy])
compare_normalization(u"Our meeting today was worse than yesterday, "
"I'm scared of meeting the clients tomorrow.")
표제어:
['-PRON-', 'meeting', 'today', 'be', 'bad', 'than', 'yesterday', ',', '-PRON-', 'be', 'scared', 'of', 'meet', 'the', 'client', 'tomorrow', '.']
어간:
['our', 'meet', 'today', 'wa', 'wors', 'than', 'yesterday', ',', 'i', 'am', 'scare', 'of', 'meet', 'the', 'client', 'tomorrow', '.']
sckit-learn 에는 두 정규화 방법이 구현되어 있지않지만, 커스토마이징 해서, 사용가능하다.
# 요구사항: CountVectorizer의 정규식 기반 토큰 분할기를 사용하고
# spacy에서 표제어 추출 기능만 이용합니다.
# 이렇게하려고 en_nlp.tokenizer(spacy 토큰 분할기)를
# 정규식 기반의 토큰 분할기로 바꿉니다
import re
# CountVectorizer에서 사용되는 정규식
regexp = re.compile('(?u)\\b\\w\\w+\\b')
# spacy의 언어 모델을 로드하고 원본 토큰 분할기를 저장합니다
en_nlp = en_core_web_sm.load()
old_tokenizer = en_nlp.tokenizer
# 정규식을 사용한 토큰 분할기를 바꿉니다
en_nlp.tokenizer = lambda string: old_tokenizer.tokens_from_list(
regexp.findall(string))
# spacy 문서 처리 파이프라인을 사용해 자작 토큰 분할기를 만듭니다
# (우리만의 토큰 분할기를 사용합니다)
def custom_tokenizer(document):
# doc_spacy = en_nlp(document, entity=False, parse=False)
doc_spacy = en_nlp(document)
return [token.lemma_ for token in doc_spacy]
# 자작 토큰 분할기를 사용해 CountVectorizer 객체를 만듭니다
lemma_vect = CountVectorizer(tokenizer=custom_tokenizer, min_df=5)
# # 표제어 추출이 가능한 CountVectorizer 객체로 text_train을 변환합니다
# X_train_lemma = lemma_vect.fit_transform(text_train)
# print("X_train_lemma.shape: {}".format(X_train_lemma.shape))
# # 비교를 위해 표준 CountVectorizer를 사용합니다
# vect = CountVectorizer(min_df=5).fit(text_train)
# X_train = vect.transform(text_train)
# print("X_train.shape: {}".format(X_train.shape))
spacy import 에 문제가 있어서…일단…건너뛴다.
이 외에도, KoNLPy (형태소 분석기 = 한국어 전용 어간분석기) 를 사용할 수 있고, 실제로도 이를 많이 사용한다.
그러나, 현재 실습 환경이 Window 인 관계로, 생략한다. 이는 추후 Collab 에서 활용하도록 한다
“KoNLPy의 Mecab() 클래스는 윈도우에서 지원되지 않습니다.” (http://konlpy.org/ko/latest/install/)
Comments