
CatBoost Titanic
Reference
-
“https://catboost.ai/docs/”
Catboost tutorial은 상기 주소를 참조했습니다.
import pandas as pd
train = pd.read_csv('../dataset/titanic_train.csv')
test = pd.read_csv('../dataset/titanic_test.csv')
print(train.shape,test.shape)
(891, 12) (418, 11)
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set() # setting seaborn default for plots
posting 목적상, EDA 부분은 생략합니다. 원본을 참조하시면, 훨씬 훌륭하게 잘 정리되어 있습니다.
1. Feature 추가
train_test_data = [train, test] # combining train and test dataset
for dataset in train_test_data:
dataset['Title'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
train['Title'].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Col 2
Major 2
Don 1
Countess 1
Ms 1
Sir 1
Capt 1
Lady 1
Mme 1
Jonkheer 1
Name: Title, dtype: int64
Title map
Mr : mr
Miss : miss
Mrs: mrs
Others: others
단순한 categorical 하게 컬럼값을 처리한다.
def apply_title(x):
if x == 'Mr':
rslt = 'mr'
elif x =='Miss':
rslt = 'miss'
elif x == 'Mrs':
rslt = 'mrs'
else :
rslt = 'others'
return rslt
train.Title.value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Col 2
Major 2
Don 1
Countess 1
Ms 1
Sir 1
Capt 1
Lady 1
Mme 1
Jonkheer 1
Name: Title, dtype: int64
train.Title.map(lambda x : apply_title(x))
0 mr
1 mrs
2 miss
3 mrs
4 mr
...
886 others
887 miss
888 miss
889 mr
890 mr
Name: Title, Length: 891, dtype: object
for dataset in train_test_data:
dataset['New_Title'] = dataset.apply(lambda x : apply_title(x['Title']),axis=1)
# delete unnecessary feature from dataset
train.drop('Name', axis=1, inplace=True)
test.drop('Name', axis=1, inplace=True)
train.drop('Title', axis=1, inplace=True)
test.drop('Title', axis=1, inplace=True)
2.Null 처리
# fill missing age with median age for each title (Mr, Mrs, Miss, Others)
train["Age"].fillna(train.groupby("New_Title")["Age"].transform("median"), inplace=True)
test["Age"].fillna(test.groupby("New_Title")["Age"].transform("median"), inplace=True)
# train.head(30)
print(train.groupby("New_Title")["Age"].agg("median"))
train.groupby("New_Title")["Age"].transform("median")[0:10] ## provide median value associated with Title-Age per each line
New_Title
miss 21.0
mr 30.0
mrs 35.0
others 9.0
Name: Age, dtype: float64
0 30.0
1 35.0
2 21.0
3 35.0
4 30.0
5 30.0
6 30.0
7 9.0
8 35.0
9 35.0
Name: Age, dtype: float64
more than 50% of 1st class are from S embark
more than 50% of 2nd class are from S embark
more than 50% of 3rd class are from S embark
fill out missing embark with S embark
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
train.head()
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | New_Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | mr |
| 1 | 2 | 1 | 1 | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | mrs |
| 2 | 3 | 1 | 3 | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | miss |
| 3 | 4 | 1 | 1 | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | mrs |
| 4 | 5 | 0 | 3 | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | mr |
3. Feature engineering
for dataset in train_test_data:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0,
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 26), 'Age'] = 1,
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <= 36), 'Age'] = 2,
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <= 62), 'Age'] = 3,
dataset.loc[ dataset['Age'] > 62, 'Age'] = 4
# fill missing Fare with median fare for each Pclass
train["Fare"].fillna(train.groupby("Pclass")["Fare"].transform("median"), inplace=True)
test["Fare"].fillna(test.groupby("Pclass")["Fare"].transform("median"), inplace=True)
train.head(5)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | New_Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 1.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | mr |
| 1 | 2 | 1 | 1 | female | 3.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | mrs |
| 2 | 3 | 1 | 3 | female | 1.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | miss |
| 3 | 4 | 1 | 1 | female | 2.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | mrs |
| 4 | 5 | 0 | 3 | male | 2.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | mr |
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].str[:1]
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].fillna('U',inplace=False)
train["FamilySize"] = train["SibSp"] + train["Parch"] + 1
test["FamilySize"] = test["SibSp"] + test["Parch"] + 1
train.head()
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | New_Title | FamilySize | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 1.0 | 1 | 0 | A/5 21171 | 7.2500 | U | S | mr | 2 |
| 1 | 2 | 1 | 1 | female | 3.0 | 1 | 0 | PC 17599 | 71.2833 | C | C | mrs | 2 |
| 2 | 3 | 1 | 3 | female | 1.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | U | S | miss | 1 |
| 3 | 4 | 1 | 1 | female | 2.0 | 1 | 0 | 113803 | 53.1000 | C | S | mrs | 2 |
| 4 | 5 | 0 | 3 | male | 2.0 | 0 | 0 | 373450 | 8.0500 | U | S | mr | 1 |
features_drop = ['Ticket', 'SibSp', 'Parch']
train = train.drop(features_drop, axis=1)
test = test.drop(features_drop, axis=1)
train = train.drop(['PassengerId'], axis=1)
Fare feature looks having correlation with Surviced. so Check the outlier!!
train.Fare.describe().apply(lambda x : "{:.4f}".format(x))
count 891.0000
mean 32.2042
std 49.6934
min 0.0000
25% 7.9104
50% 14.4542
75% 31.0000
max 512.3292
Name: Fare, dtype: object
def ourlier_index(df,column,p):
q3 = df[column].quantile(0.75)
q1 = df[column].quantile(0.25)
iqr = q3 - q1
max_limit_val = q3+(iqr*p)
min_limit_val = 0 if q1-(iqr*p) < 0 else q1-(iqr*p)
a = (min_limit_val,max_limit_val)
print("min_limit_val {}".format(a[0]),"\t","max_limit_val {}".format(a[1]))
ix = df.loc[df.Fare < a[0]].index | df.loc[df.Fare > a[1]].index
left_ix = set(df.index)-set(ix)
return left_ix
train.groupby(by='Survived').Fare.describe().stack().apply(lambda x : "{:.4f}".format(x))
Survived
0 count 549.0000
mean 22.1179
std 31.3882
min 0.0000
25% 7.8542
50% 10.5000
75% 26.0000
max 263.0000
1 count 342.0000
mean 48.3954
std 66.5970
min 0.0000
25% 12.4750
50% 26.0000
75% 57.0000
max 512.3292
dtype: object
survived = 1,0 에 따라 아웃라이어가 다를 수 있으니, 다르게 접근하여 아웃라이어를 처리한다.
## when you want to find outlier and remove outlier value, run this code~
left_survive_ix = ourlier_index(train[train.loc[:,"Survived"]==1],"Fare",2.5)
left_die_ix = ourlier_index(train[train.loc[:,"Survived"]==0],"Fare",2.5)
print(len(left_survive_ix),len(left_die_ix))
left_survive_ix.intersection(left_die_ix) ## no dup index
train_01 = pd.concat([train.iloc[list(left_survive_ix)],train.iloc[list(left_die_ix)]],axis=0)
train_01.reset_index(drop=True,inplace=True)
print(train_01.shape)
train_01.head()
min_limit_val 0 max_limit_val 168.3125
min_limit_val 0 max_limit_val 71.3645
328 521
(849, 9)
| Survived | Pclass | Sex | Age | Fare | Cabin | Embarked | New_Title | FamilySize | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | female | 3.0 | 71.2833 | C | C | mrs | 2 |
| 1 | 1 | 3 | female | 1.0 | 7.9250 | U | S | miss | 1 |
| 2 | 1 | 1 | female | 2.0 | 53.1000 | C | S | mrs | 2 |
| 3 | 1 | 3 | female | 2.0 | 11.1333 | U | S | mrs | 3 |
| 4 | 1 | 2 | female | 0.0 | 30.0708 | U | C | mrs | 2 |
print(train.shape)
print("---"*20)
print(test.shape)
print("---"*20)
print(train.isnull().sum())
print("---"*20)
print(test.isnull().sum())
(891, 9)
------------------------------------------------------------
(418, 9)
------------------------------------------------------------
Survived 0
Pclass 0
Sex 0
Age 0
Fare 0
Cabin 0
Embarked 0
New_Title 0
FamilySize 0
dtype: int64
------------------------------------------------------------
PassengerId 0
Pclass 0
Sex 0
Age 0
Fare 0
Cabin 0
Embarked 0
New_Title 0
FamilySize 0
dtype: int64
data 전처리 끝난 data 저장 및 불러오기
# train = pd.read_csv('../dataset/titanic_train.csv')
# test = pd.read_csv('../dataset/titanic_test.csv')
train.to_csv("../dataset/titanic_processed_train.csv",index=False,encoding="UTF8")
test.to_csv("../dataset/titanic_processed_test.csv",index=False,encoding="UTF8")
train = pd.read_csv('../dataset/titanic_processed_train.csv')
test = pd.read_csv('../dataset/titanic_processed_test.csv')
train_data = train.drop('Survived', axis=1)
target = train['Survived']
test_data = test.drop("PassengerId", axis=1).copy()
print(train_data.shape,target.shape)
print(test_data.shape)
(891, 8) (891,)
(418, 8)
numeric, categorical column 구분
cat_cols = train_data.columns[train_data.dtypes == 'object'].to_list()
num_cols = train_data.columns[train_data.dtypes != 'object'].to_list()
len(train.columns)
len(cat_cols)+len(num_cols)
8
Scaling
from sklearn.preprocessing import MinMaxScaler,OneHotEncoder,StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
# from imblearn.ensemble import BalancedRandomForestclassifier
# import xgboost as sgb
target.sum()
342
train_data.head()
| Pclass | Sex | Age | Fare | Cabin | Embarked | New_Title | FamilySize | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | male | 1.0 | 7.2500 | U | S | mr | 2 |
| 1 | 1 | female | 3.0 | 71.2833 | C | C | mrs | 2 |
| 2 | 3 | female | 1.0 | 7.9250 | U | S | miss | 1 |
| 3 | 1 | female | 2.0 | 53.1000 | C | S | mrs | 2 |
| 4 | 3 | male | 2.0 | 8.0500 | U | S | mr | 1 |
scaler = MinMaxScaler()
x_train_scaled = scaler.fit_transform(train_data[num_cols])
test_data_scaled = scaler.transform(test_data[num_cols])
train_data[num_cols] = x_train_scaled
test_data[num_cols] = test_data_scaled
train_data.head(2)
| Pclass | Sex | Age | Fare | Cabin | Embarked | New_Title | FamilySize | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | male | 0.25 | 0.014151 | U | S | mr | 0.1 |
| 1 | 0.0 | female | 0.75 | 0.139136 | C | C | mrs | 0.1 |
test_data.head(2)
| Pclass | Sex | Age | Fare | Cabin | Embarked | New_Title | FamilySize | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | male | 0.50 | 0.015282 | U | Q | mr | 0.0 |
| 1 | 1.0 | female | 0.75 | 0.013663 | U | S | mrs | 0.1 |
1.Catboosting Modeling - Basic
import catboost
print(catboost.__version__)
!python --version
0.23
Python 3.7.7
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(train_data, target, train_size=0.75, random_state=42)
from catboost import CatBoostClassifier, Pool, cv
from sklearn.metrics import accuracy_score
train_pool = Pool(X_train,y_train, cat_features=cat_cols)
eval_pool = Pool(X_validation , y_validation , cat_features=cat_cols)
params = {'iterations':200,
'random_seed':63,
'learning_rate':0.02,
'loss_function':'Logloss', ## 사실 Default 값은 Logloss 이다. 만약 CatBoostRegressor 였으면, RMSE 이다.
'custom_metric':['Logloss','AUC'],##, '
'early_stopping_rounds':20,
'use_best_model': True,
'task_type':"GPU",
'bagging_temperature':1,
'verbose':False}
## model : use_best_model = false 인 모델
model = CatBoostClassifier(**params)
model.fit(train_pool, eval_set=eval_pool,plot=True) ## ,save_snapshot=True
print('Simple model validation accuracy: {:.4}'.format(accuracy_score(y_validation, model.predict(X_validation))))
Simple model validation accuracy: 0.8117
model.best_score_
{'learn': {'Logloss': 0.32636105657337666, 'AUC': 0.9368255734443665},
'validation': {'Logloss': 0.413340855072432, 'AUC': 0.8898625075817108}}
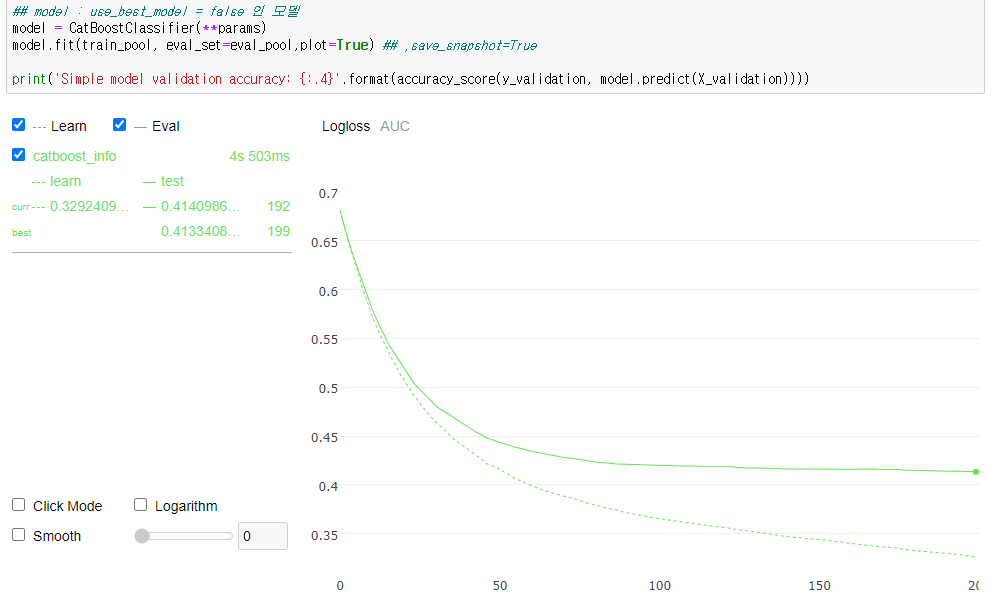
특이사항
1) catboost lib 에서, 제공하는 Pool() 을 이용 편하게 묶어서 다닐 수 있다.
2) 모델에게 반드시 cat_features=cat_features 을 명시해야 한다. (fit method 에서도 가능하고, 상기 예제에서는 Pool()에서 선언함)
3) plot=True 란 명령어 하나로, 쉽게 시각화 가능하다.
4) scikit-learn 의 여타 library와 마찬가지로, dict_typing 형태의 상속함수를 사용하기 때문에, fit,predict,predict_proba() 등이 가능하다.
5) parmeter 에 early_stopping_rounds, od_type , od_pval 같은 Overfitting detector 를 쉽게 사용할 수 있다.
2.Catboosting Modeling - CV 평가
params.update({'early_stopping_rounds':None})
cv_data = cv(
params = params,
# pool = Pool(X, label=y, cat_features=cat_features), ## fit method 구문의 역할을 한다.
pool = train_pool, ## fit method 구문의 역할을 한다.
fold_count=3,
shuffle=True,
partition_random_seed=0,
plot=True,
stratified=True,
verbose=False
)
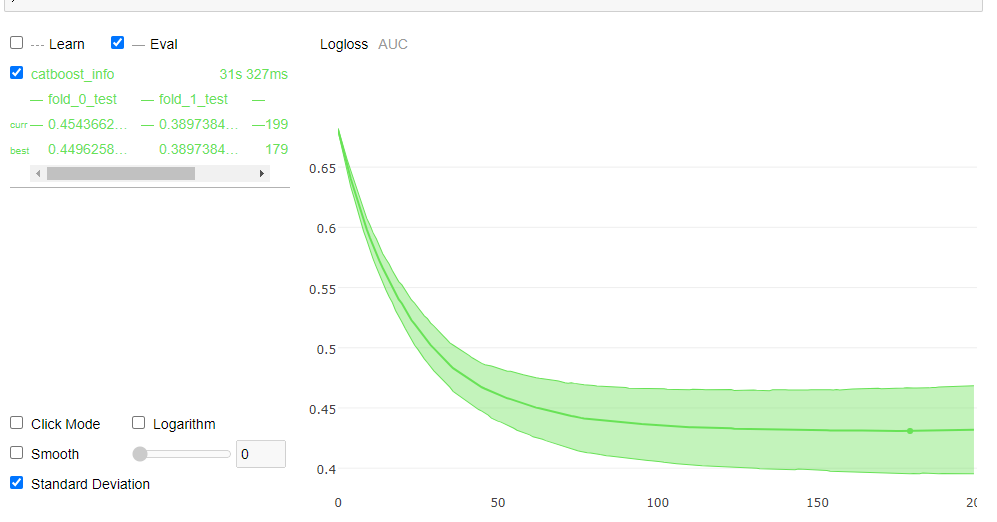
MetricVisualizer(layout=Layout(align_self='stretch', height='500px'))
## 요약된 결과보기
cv_data.head()
| iterations | test-Logloss-mean | test-Logloss-std | train-Logloss-mean | train-Logloss-std | test-AUC-mean | test-AUC-std | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.681265 | 0.001101 | 0.680363 | 0.000513 | 0.830223 | 0.016995 |
| 1 | 1 | 0.670393 | 0.002176 | 0.668140 | 0.002284 | 0.834873 | 0.022364 |
| 2 | 2 | 0.659754 | 0.004702 | 0.656341 | 0.003956 | 0.837594 | 0.025172 |
| 3 | 3 | 0.649844 | 0.005210 | 0.645445 | 0.003871 | 0.838677 | 0.020977 |
| 4 | 4 | 0.640309 | 0.006798 | 0.635021 | 0.005017 | 0.842693 | 0.023301 |
import numpy as np
best_value = np.min(cv_data['test-Logloss-mean'])
best_iter = np.argmin(cv_data['test-Logloss-mean'])
print('Best validation Logloss score, not stratified: {:.4f}±{:.4f} on step {}'.format(
best_value,cv_data['test-Logloss-std'][best_iter], best_iter)
)
Best validation Logloss score, not stratified: 0.4309±0.0355 on step 179
np.max(cv_data['test-Logloss-mean'])
0.6812654777127548
CV 결과를 통해 평균적으로 fitted 된 모델의 성능을 알 수 있다.
3.Catboosting Modeling - Hyper parameter 튜닝
Hyper parameter 튜닝은 별도의 library를 활용해서, 하는데 error 부분이 있기에 여기선 생략한다.
from catboost import Pool as pool
import hyperopt
from hyperopt import hp, fmin, tpe, STATUS_OK, Trials
params
{'iterations': 200,
'random_seed': 63,
'learning_rate': 0.02,
'loss_function': 'Logloss',
'custom_metric': ['Logloss', 'AUC'],
'early_stopping_rounds': None,
'use_best_model': True,
'task_type': 'GPU',
'bagging_temperature': 1,
'verbose': False}
# number of random sampled hyperparameters
N_HYPEROPT_PROBES = 15
# the sampling aplgorithm
HYPEROPT_ALGO = tpe.suggest
def get_catboost_params(space):
tunning_params = dict()
tunning_params['learning_rate'] = space['learning_rate']
tunning_params['depth'] = int(space['depth'])
tunning_params['l2_leaf_reg'] = space['l2_leaf_reg']
tunning_params['loss_function'] = 'Logloss'
# tunning_params['one_hot_max_size'] = space['one_hot_max_size']
return tunning_params
obj_call_count = 0
cur_best_loss = np.inf
log_writer = open( 'catboost-hyperopt-log.txt', 'w' )
def objective(space):
global obj_call_count, cur_best_loss
obj_call_count += 1
print('\nCatBoost objective call #{} cur_best_loss={:7.5f}'.format(obj_call_count,cur_best_loss) )
params = get_catboost_params(space)
# sorted_params = sorted(space.iteritems(), key=lambda z: z[0])
# params_str = str.join(' ', ['{}={}'.format(k, v) for k, v in sorted_params])
# print('Params: {}'.format(params_str) )
model = CatBoostClassifier(iterations=2000,
learning_rate=params['learning_rate'],
depth =int(params['depth']),
task_type = "GPU",
eval_metric = "AUC",
l2_leaf_reg=params['l2_leaf_reg'],
bagging_temperature=1,
use_best_model=True)
model.fit(train_pool, eval_set=eval_pool, silent=True)
#y_pred = model.predict(df_test_.drop('loss', axis=1))
val_loss = model.best_score_['validation']['Logloss']
if val_loss<cur_best_loss:
cur_best_loss = val_loss
return{'loss':cur_best_loss, 'status': STATUS_OK }
space ={
'depth': hp.quniform("depth", 4, 12, 1),
'learning_rate': hp.loguniform('learning_rate', -3.0, -0.7),
'l2_leaf_reg': hp.uniform('l2_leaf_reg', 1, 10)
}
HYPEROPT_ALGO
<function hyperopt.tpe.suggest(new_ids, domain, trials, seed, prior_weight=1.0, n_startup_jobs=20, n_EI_candidates=24, gamma=0.25, verbose=True)>
trials = Trials()
best = hyperopt.fmin(fn=objective,space=space,algo=HYPEROPT_ALGO,max_evals=N_HYPEROPT_PROBES,trials=trials)
print('-'*50)
print('The best params:')
print( best )
print('\n\n')
CatBoost objective call #3 cur_best_loss= inf
CatBoost objective call #4 cur_best_loss=0.39896
CatBoost objective call #5 cur_best_loss=0.39896
CatBoost objective call #6 cur_best_loss=0.39896
CatBoost objective call #7 cur_best_loss=0.39896
27%|█████████████ | 4/15 [06:09<16:31, 90.16s/trial, best loss: 0.3989643387730346]
튜닝은 중간결과를 캡쳐했지만, 확실히 더 나은 성능을 보였다.
최종 제출 결과 만들기
prediction = model.predict(test_data)
submission = pd.DataFrame({
"PassengerId": test["PassengerId"],
"Survived": prediction
})
submission.to_csv('../dataset/submission.csv', index=False) ## 0.79425 달성!!
submission = pd.read_csv('../dataset/submission.csv')
submission.head()
0.79425 로 Stacking과 동일한 결과를 얻었다.
Comments