
Time Series Analysis using Keras Conv1D
import keras
keras.__version__
Using TensorFlow backend.
'2.2.4'
Conv1D 실습을 위한 데이터 불러오기
numpy version 문제로, imdb.load 가 수행되지 않는 경우가 있다.
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000 # 특성으로 사용할 단어의 수
max_len = 500 # 확인결과, 각 sample 문장에서, [-500:] 으로, 단어를 불러온다.
import numpy as np
# save np.load
np_load_old = np.load
# modify the default parameters of np.load
np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k)
# call load_data with allow_pickle implicitly set to true
print('데이터 로드...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), '훈련 시퀀스')
print(len(x_test), '테스트 시퀀스')
# restore np.load for future normal usage (다시 numpy.load 를 원래데로 원복한다.)
np.load = np_load_old
데이터 로드...
25000 훈련 시퀀스
25000 테스트 시퀀스
print('시퀀스 패딩 (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)
print('x_train 크기:', x_train.shape)
print('x_test 크기:', x_test.shape)
시퀀스 패딩 (samples x time)
x_train 크기: (25000, 500)
x_test 크기: (25000, 500)
print("x_train_ndim:{}\tx_train_shape:{}\tx_train_type:{}".format(x_train.ndim,x_train.shape,type(x_train)))
for i in range(10,20):
print("x_train {}째 데이터 길이 {}".format(i,len(x_train[i])))
x_train_ndim:2 x_train_shape:(25000, 500) x_train_type:<class 'numpy.ndarray'>
x_train 10째 데이터 길이 500
x_train 11째 데이터 길이 500
x_train 12째 데이터 길이 500
x_train 13째 데이터 길이 500
x_train 14째 데이터 길이 500
x_train 15째 데이터 길이 500
x_train 16째 데이터 길이 500
x_train 17째 데이터 길이 500
x_train 18째 데이터 길이 500
x_train 19째 데이터 길이 500
실제 1D Conv1D 모델 학습 및 만들기
1D 컨브넷은 5장에서 사용한 2D 컨브넷과 비슷한 방식으로 구성한다.
Conv1D와 MaxPooling1D 층을 쌓고 전역 풀링 층이나 Flatten 층으로 마친다.
- layers.Conv1D - input_shape : 3D tensor 로서, (samples,time,features) 크기
- layers.Conv2D - input_shape : 3D tensor 로서, (height,width,channels)
channels = RGB를 받음. Conv2D의 경우, Convnet 구조상 배치 개념으로 돌지 않기 때문에, samples 자리가 없다.하지만 3D tensor 값을 입력으로 받는다는 점은 동일한다.
- layers.Conv1D - ouput_shape : 3D tensor 로서, (samples,time,features) 크기
- layers.Conv2D - ouput_shape : 3D tensor 로서, (height,width,channels) 를 출력함. 마지막 channel 는 feature 차원이다. 책으로는 chnnel 이라 표현했지만, feature차원이 더 맞는듯
ex> layers.Conv2D(32,(3,3),actication=’relu’ ~ ) 의 첫번째 parameter 32 를 의미한다.
한 가지 다른 점은 1D 컨브넷에 큰 합성곱 윈도우를 사용할 수 있다점이 특이점이다.
2D 합성곱 층에서 3 × 3 합성곱 윈도우는 3 × 3 = 9 특성을 고려한다 하지만, 1D 합성곱 층에서 크기 3인 합성곱 윈도우는 3개의 특성만 고려한다.
그래서 1D 합성곱에 크기 7이나 9의 윈도우를 사용할 수 있습니다.
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Embedding(max_features, 128, input_length=max_len)) ## input:(batches,sequence_length = 500) / output:(batches,sequence_length=500,embedding_dimensionality=128)
model.add(layers.Conv1D(32, 7, activation='relu')) ## 32 feature 특성공간으로 추출하며, window = 7 사용한다.
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D()) ## 다음에 있는 Dense층에 넣기 위해 추가되었다.
model.add(layers.Dense(1))
model.summary()
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 500, 128) 1280000
_________________________________________________________________
conv1d_1 (Conv1D) (None, 494, 32) 28704
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 98, 32) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 92, 32) 7200
_________________________________________________________________
global_max_pooling1d_1 (Glob (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 1,315,937
Trainable params: 1,315,937
Non-trainable params: 0
_________________________________________________________________
(None, 494, 32) 494 = 500-7+1
(None, 98, 32) 98 = 494//5 응답맵(494) 에서, 5개씩 묶어서, 5개당 1개 max 값 pooling함
global_max_pooling1d_1 (Glob (None, 32) 응답맴 92 중 1개 추출함. 사실상 flatten 효과
model.compile(optimizer=RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\test\lib\site-packages\tensorflow\python\ops\math_grad.py:102: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 6s 292us/step - loss: 0.8337 - acc: 0.5095 - val_loss: 0.6874 - val_acc: 0.5652
Epoch 2/10
20000/20000 [==============================] - 2s 108us/step - loss: 0.6699 - acc: 0.6386 - val_loss: 0.6641 - val_acc: 0.6584
Epoch 3/10
20000/20000 [==============================] - 2s 109us/step - loss: 0.6234 - acc: 0.7532 - val_loss: 0.6076 - val_acc: 0.7424
Epoch 4/10
20000/20000 [==============================] - 2s 108us/step - loss: 0.5251 - acc: 0.8077 - val_loss: 0.4838 - val_acc: 0.8070
Epoch 5/10
20000/20000 [==============================] - 2s 107us/step - loss: 0.4129 - acc: 0.8477 - val_loss: 0.4308 - val_acc: 0.8300
Epoch 6/10
20000/20000 [==============================] - 2s 107us/step - loss: 0.3494 - acc: 0.8664 - val_loss: 0.4142 - val_acc: 0.8356
Epoch 7/10
20000/20000 [==============================] - 2s 107us/step - loss: 0.3097 - acc: 0.8635 - val_loss: 0.4377 - val_acc: 0.8226
Epoch 8/10
20000/20000 [==============================] - 2s 108us/step - loss: 0.2788 - acc: 0.8633 - val_loss: 0.4084 - val_acc: 0.8210
Epoch 9/10
20000/20000 [==============================] - 2s 106us/step - loss: 0.2545 - acc: 0.8468 - val_loss: 0.4528 - val_acc: 0.7856
Epoch 10/10
20000/20000 [==============================] - 2s 110us/step - loss: 0.2310 - acc: 0.8258 - val_loss: 0.4999 - val_acc: 0.7598
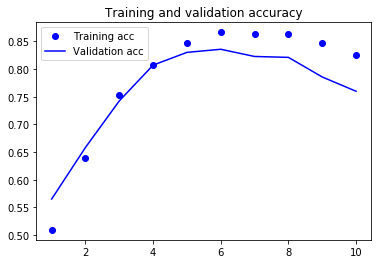
적절한 epoch 는 6에 해당함을 알 수 있다.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
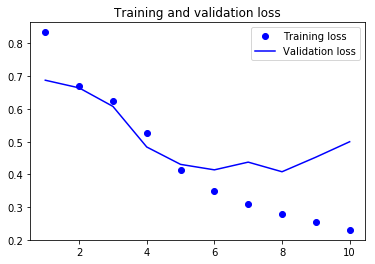
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
CNN과 RNN을 연결하여 긴 시퀀스를 처리하기
1D 컨브넷이 입력 패치를 독립적으로 처리하기 때문에 RNN과 달리 (합성곱 윈도우 크기의 범위를 넘어선) 타임스텝의 순서에 민감하지 않습니다. 물론 장기간 패턴을 인식하기 위해 많은 합성곱 층과 풀링 층을 쌓을 수 있습니다. 상위 층은 원본 입력에서 긴 범위를 보게 될 것입니다. 이런 방법은 순서를 감지하기엔 부족합니다. 온도 예측 문제에 1D 컨브넷을 적용하여 이를 확인해 보겠습니다. 이 문제는 순서를 감지해야 좋은 예측을 만들어 낼 수 있습니다. 다음은 이전에 정의한 float_data, train_gen, val_gen, val_steps를 다시 사용합니다:
import os
data_dir = 'D:/★2020_ML_DL_Project/Alchemy/dataset/jena_climate'
fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')
fname
'D:/★2020_ML_DL_Project/Alchemy/dataset/jena_climate\\jena_climate_2009_2016.csv'
f = open(fname)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
print(header)
print(len(lines))
['"Date Time"', '"p (mbar)"', '"T (degC)"', '"Tpot (K)"', '"Tdew (degC)"', '"rh (%)"', '"VPmax (mbar)"', '"VPact (mbar)"', '"VPdef (mbar)"', '"sh (g/kg)"', '"H2OC (mmol/mol)"', '"rho (g/m**3)"', '"wv (m/s)"', '"max. wv (m/s)"', '"wd (deg)"']
420551
print(len(header))
15
import numpy as np
float_data = np.zeros((len(lines), len(header) - 1)) # len(header) - 1 = 14임.
print("float_data_shape {}".format(float_data.shape))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]] # Date Time 은 제외하고, 값에 넣고 있음.
float_data[i, :] = values
float_data_shape (420551, 14)
print("ndim:{}".format(float_data.ndim)," shape:{}".format(float_data.shape))
ndim:2 shape:(420551, 14)
np.set_printoptions(precision=6)
float_data[0]
array([ 9.96520e+02, -8.02000e+00, 2.65400e+02, -8.90000e+00,
9.33000e+01, 3.33000e+00, 3.11000e+00, 2.20000e-01,
1.94000e+00, 3.12000e+00, 1.30775e+03, 1.03000e+00,
1.75000e+00, 1.52300e+02])
데이터 전처리
각 시계열 특성에 대해 평균을 빼고 표준 편차로 나누어 전처리합니다.
처음 200,000개 타임스텝을 훈련 데이터로 사용할 것이므로 전체 데이터에서 200,000개만 사용하여 평균과 표준 편차를 계산한다.
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
다음은 여기서 사용할 제너레이터입니다. 이 제너레이터 함수는 (samples, targets) 튜플을 반복적으로 반환합니다. samples는 입력 데이터로 사용할 배치이고 targets은 이에 대응되는 타깃 온도의 배열입니다. 이 제너레이터 함수는 다음과 같은 매개변수가 있습니다:
data: 코드 6-32에서 정규화한 부동 소수 데이터로 이루어진 원본 배열lookback: 입력으로 사용하기 위해 거슬러 올라갈 타임스텝delay: 타깃으로 사용할 미래의 타임스텝min_index와max_index: 추출할 타임스텝의 범위를 지정하기 위한data배열의 인덱스. 검증 데이터와 테스트 데이터를 분리하는 데 사용합니다.shuffle: 샘플을 섞을지 시간 순서대로 추출할지 결정합니다.batch_size: 배치의 샘플 수step: 데이터를 샘플링할 타임스텝 간격. 한 시간에 하나의 데이터 포인트를 추출하기 위해 6으로 지정하겠습니다.
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
# 전체 검증 세트를 순회하기 위해 val_gen에서 추출할 횟수
val_steps = (300000 - 200001 - lookback) // batch_size
# 전체 테스트 세트를 순회하기 위해 test_gen에서 추출할 횟수
test_steps = (len(float_data) - 300001 - lookback) // batch_size
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Conv1D(32, 5, activation='relu',
input_shape=(None, float_data.shape[-1])))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
Epoch 1/20
500/500 [==============================] - 9s 19ms/step - loss: 0.4201 - val_loss: 0.4457
Epoch 2/20
500/500 [==============================] - 9s 18ms/step - loss: 0.3637 - val_loss: 0.4516
Epoch 3/20
500/500 [==============================] - 9s 18ms/step - loss: 0.3380 - val_loss: 0.4850
Epoch 4/20
500/500 [==============================] - 9s 18ms/step - loss: 0.3215 - val_loss: 0.4670
Epoch 5/20
500/500 [==============================] - 9s 18ms/step - loss: 0.3065 - val_loss: 0.4870
Epoch 6/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2975 - val_loss: 0.4775
Epoch 7/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2899 - val_loss: 0.4675
Epoch 8/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2832 - val_loss: 0.4955
Epoch 9/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2755 - val_loss: 0.4806
Epoch 10/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2718 - val_loss: 0.4786
Epoch 11/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2679 - val_loss: 0.5100
Epoch 12/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2624 - val_loss: 0.4871
Epoch 13/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2577 - val_loss: 0.4802
Epoch 14/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2549 - val_loss: 0.4868
Epoch 15/20
500/500 [==============================] - 9s 19ms/step - loss: 0.2527 - val_loss: 0.4989
Epoch 16/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2501 - val_loss: 0.5348
Epoch 17/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2461 - val_loss: 0.4932
Epoch 18/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2434 - val_loss: 0.4905
Epoch 19/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2422 - val_loss: 0.4891
Epoch 20/20
500/500 [==============================] - 9s 18ms/step - loss: 0.2395 - val_loss: 0.4984
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
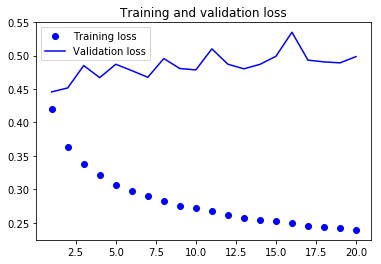
검증 MAE는 0.40 대에 머물러 있습니다. 작은 컨브넷을 사용해서 상식 수준의 기준점을 넘지 못했다.
이는 컨브넷이 입력 시계열에 있는 패턴을 보고 이 패턴의 시간 축의 위치(시작인지 끝 부분인지 등)를 고려하지 않기 때문이다.
최근 데이터 포인트일수록 오래된 데이터 포인트와는 다르게 해석해야 하는데 각 시간축(5개단위)의 특성만을 나열했기 때문으로도 해석가능한다.
때문에 컨브넷이 의미 있는 결과를 만들지 못하고, 시간 순서를 고려하기 위해서는 순환층을 넣어야 한다.
(이런 컨브넷의 한계는 IMDB 데이터에서는 문제가 되지 않습니다. 긍정 또는 부정적인 감성과 연관된 키워드 패턴의 중요성은 입력 시퀀스에 나타난 위치와 무관하기 때문이다.)
그럼에도, 불구하고, Conc1D 를 사용하는 이유는 속도와 경량성 때문이라고 책에서는 말하고 있다. 그리고, 이를 보완하기 위한 일반적인 방법은 GRU 같은 순환층을 더 쌓는 것이라 말한다.
본문인용
1D 컨브넷을 RNN 이전에 전처리 단계로 사용하는 것입니다. 수천 개의 스텝을 가진 시퀀스 같이 RNN으로 처리하기엔 현실적으로 너무 긴 시퀀스를 다룰 때 특별히 도움이 됩니다. 컨브넷이 긴 입력 시퀀스를 더 짧은 고수준 특성의 (다운 샘플된) 시퀀스로 변환합니다. 추출된 특성의 시퀀스는 RNN 파트의 입력이 됩니다.
이 기법이 연구 논문이나 실전 애플리케이션에 자주 등장하지는 않습니다. 아마도 널리 알려지지 않았기 때문일 것입니다. 이 방법은 효과적이므로 많이 사용되기를 바랍니다. 온도 예측 문제에 적용해 보죠. 이 전략은 훨씬 긴 시퀀스를 다룰 수 있으므로 더 오래전 데이터를 바라보거나(데이터 제너레이터의 lookback 매개변수를 증가시킵니다), 시계열 데이터를 더 촘촘히 바라볼 수 있습니다(제너레이터의 step 매개변수를 감소시킵니다). 여기서는 그냥 step을 절반으로 줄여서 사용하겠습니다. 온도 데이터가 30분마다 1 포인트씩 샘플링되기 때문에 결과 시계열 데이터는 두 배로 길어집니다. 앞서 정의한 제너레이터 함수를 다시 사용합니다.
generator_test 로 어떤 값들이 yield 될지 유추해본다.
def generator_test(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
return samples, targets
lookback = 1440 ## 10일치인것은 그대로이나, 30분단위로 엮은 것임을 알아야 한다.
step = 3
delay = 144
batch_size = 128
t_sample,t_targets = generator_test(float_data, # 변환코자 하는 data 삽입
lookback=lookback, # 10일전 데이터로 돌아간다.
delay=delay,# 144 값을 넣으면, 24시간이 지난 데이터가 타깃이 된다는 뜻
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
t_sample.shape
(128, 480, 14)
t_targets.shape
(128,)
# 이전에는 6이었습니다(시간마다 1 포인트); 이제는 3 입니다(30분마다 1 포인트)
step = 3
lookback = 1440 # 변경 안 됨
delay = 144 # 변경 안 됨
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step)
val_steps = (300000 - 200001 - lookback) // 128
test_steps = (len(float_data) - 300001 - lookback) // 128
이 모델은 두 개의 Conv1D 층 다음에 GRU 층을 놓았습니다:
model = Sequential()
model.add(layers.Conv1D(32, 5, activation='relu', ## 32 반응feature 특성, window=5
input_shape=(None, float_data.shape[-1]))) ## input_shape:(samples,time_stamp,features) / (128,480,14) shape 이 input 값임.
# input_shape=(480, float_data.shape[-1]))) ## input_shape:(samples,time_stamp,features) / (128,480,14) shape 이 input 값임.
## 480 의 timestamp 에 윈도우 값 5를 적용하게 됨.
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_10 (Conv1D) (None, None, 32) 2272
_________________________________________________________________
max_pooling1d_6 (MaxPooling1 (None, None, 32) 0
_________________________________________________________________
conv1d_11 (Conv1D) (None, None, 32) 5152
_________________________________________________________________
gru_3 (GRU) (None, 32) 6240
_________________________________________________________________
dense_5 (Dense) (None, 1) 33
=================================================================
Total params: 13,697
Trainable params: 13,697
Non-trainable params: 0
_________________________________________________________________
conv1d_6 (Conv1D):(None, None, 32) 2번째 None 은 왜, None으로 표시되는지 알지 못한다.
확인해보니, input_shape 파라미터를 (None,14) 이라서, 그렇다. (480,14) 를 하면 480-5 = 475 로 summary에서 표시된다.
max_pooling1d_4 은 기본적으로 input_shape 의 변화가 없다. parameter 양이 줄뿐.
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
Epoch 1/20
500/500 [==============================] - 86s 171ms/step - loss: 0.2396 - val_loss: 0.2858
Epoch 2/20
500/500 [==============================] - 85s 169ms/step - loss: 0.2361 - val_loss: 0.2842
Epoch 3/20
500/500 [==============================] - 85s 169ms/step - loss: 0.2346 - val_loss: 0.2832
Epoch 4/20
500/500 [==============================] - 84s 168ms/step - loss: 0.2310 - val_loss: 0.2856
Epoch 5/20
500/500 [==============================] - 85s 170ms/step - loss: 0.2278 - val_loss: 0.2864
Epoch 6/20
500/500 [==============================] - 85s 170ms/step - loss: 0.2261 - val_loss: 0.2880
Epoch 7/20
500/500 [==============================] - 84s 168ms/step - loss: 0.2242 - val_loss: 0.2878
Epoch 8/20
500/500 [==============================] - 84s 169ms/step - loss: 0.2216 - val_loss: 0.2963
Epoch 9/20
500/500 [==============================] - 85s 170ms/step - loss: 0.2208 - val_loss: 0.2908
Epoch 10/20
500/500 [==============================] - 84s 169ms/step - loss: 0.2194 - val_loss: 0.2963
Epoch 11/20
500/500 [==============================] - 86s 172ms/step - loss: 0.2169 - val_loss: 0.2971
Epoch 12/20
500/500 [==============================] - 84s 167ms/step - loss: 0.2152 - val_loss: 0.3008
Epoch 13/20
500/500 [==============================] - 83s 167ms/step - loss: 0.2145 - val_loss: 0.3038
Epoch 14/20
500/500 [==============================] - 83s 166ms/step - loss: 0.2111 - val_loss: 0.2920
Epoch 15/20
500/500 [==============================] - 84s 167ms/step - loss: 0.2106 - val_loss: 0.2949
Epoch 16/20
500/500 [==============================] - 85s 170ms/step - loss: 0.2098 - val_loss: 0.2974
Epoch 17/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2077 - val_loss: 0.2961
Epoch 18/20
500/500 [==============================] - 83s 167ms/step - loss: 0.2065 - val_loss: 0.2977
Epoch 19/20
500/500 [==============================] - 83s 167ms/step - loss: 0.2062 - val_loss: 0.3002
Epoch 20/20
500/500 [==============================] - 83s 166ms/step - loss: 0.2045 - val_loss: 0.3066
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
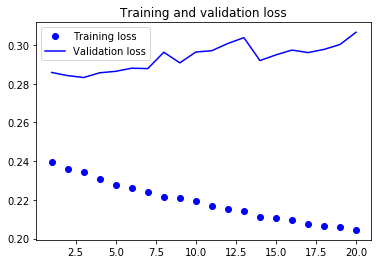
검증 손실로 비교해 보면 이 설정은 규제가 있는 GRU 모델만큼 좋지는 않습니다. 하지만 훨씬 빠르기 때문에 데이터를 두 배 더 많이 처리할 수 있다고 한다.
여기서는 큰 도움이 안 되었지만 다른 데이터셋에서는 중요할 수 있다.
정리 는 원본 책을 차용했다.
다음은 이번 절에서 배운 것들입니다.
- 2D 컨브넷이 2D 공간의 시각적 패턴을 잘 처리하는 것과 같이 1D 컨브넷은 시간에 따른 패턴을 잘 처리합니다. 1D 컨브넷은 특정 자연어 처리 같은 일부 문제에 RNN을 대신할 수 있는 빠른 모델입니다.
- 전형적으로 1D 컨브넷은 컴퓨터 비전 분야의 2D 컨브넷과 비슷하게 구성합니다.
Conv1D층과Max-Pooling1D층을 쌓고 마지막에 전역 풀링 연산이나Flatten층을 둡니다. - RNN으로 아주 긴 시퀀스를 처리하려면 계산 비용이 많이 듭니다. 1D 컨브넷은 비용이 적게 듭니다. 따라서 1D 컨브넷을 RNN 이전의 전처리 단계로 사용하는 것은 좋은 생각입니다. 시퀀스 길이를 줄이고 RNN이 처리할 유용한 표현을 추출해 줄 것입니다.
유용하고 중요한 개념이지만 여기서 다루지 않은 것은 팽창 커널을 사용한 1D 합성곱입니다.
확실히 순환layer를 add 하면, 학습시간이 매우 많이 늘어난다.
Comments